SMART Frame Selection for Action Recognition 리뷰
Updated:
SMART Frame Selection for Action Recognition 리뷰
논문 다운 링크
https://arxiv.org/pdf/2012.10671.pdf
Abstract
본 논문에서는 동작 인식의 정확성을 높이기 위해 프레임 선택 문제를 다룬다. 특히 좋은 프레임을 선택하면 잘린 동영상 영역에서도 동작 인식 성능에 도움이 된다는 것을 확인한 논문
- 좋은 프레임 선택은 동작 인식의 계산 비용을 줄일뿐만 아니라 분류하기 어려운 프레임을 제거하여 정확도를 높일 수 있다고 주장
이전 작업과 달리 프레임을 한 번에 하나씩 고려하여 선택하는 대신 공동으로 고려하는 방법을 제안
- 그 결과 스토리를 전달하는 스냅 샷처럼 “좋은” 프레임이 비디오에 더 효과적으로 분산되는 더 효율적인 선택이 가능
제안하는 프레임 선택을 SMART라고 부르며 다양한 backbone 아키텍처와 여러 benchmark (Kinetics, Something-something, UCF101)에서 테스트
- 우리는 SMART 프레임 선택이 다른 프레임 선택 전략에 비해 지속적으로 정확도를 향상시키면서 계산 비용을 4 ~ 10 배 감소
- primary goal이 recognition performance일 때 제안된 방법은 다양한 benchmark(UCF101, HMDB51, FCVID 및 ActivityNet)에서 sota model 및 다른 프레임 선택 전략보다 향상될 수 있음을 보여줌
Introduction
Video processing은 많은 계산 비용이 듦. 기존의 행동 인식은 더 큰 아키텍처를 만들어 정확성을 높이는 데 중점을 두었고 이러한 아키텍처는 프레임 또는 프레임 set(=clip)을 입력으로 받아 prediction한다. 이러한 prediction은 over time으로 aggregate된다. 프레임이나 클립의 경우는 densly나 random으로 샘플링된다.
그러나 비디오는 여러 가지 방법으로 계산 비용을 줄일 수 있는 기회를 제공함
- 첫째, 비디오에는 매우 일시적으로 중복된 데이터가 포함되어 있어 많은 정보를 잃지 않고 부분을 건너 뛰기 쉽다 (Fan et al. 2018)
- 둘째, 비디오의 일부 부분은 내용, 흐림, 가림 등과 같은 기타 현상으로 인해 다른 부분보다 더 차별적일 수 있다
- Huang et al. (2018)은 oracle을 사용하여 프레임 (또는 클립)을 최적으로 선택하는 것이 전체 비디오를 사용하는 것보다 더 정확한 분류 결과를 생성한다는 것을 실험적으로 보여줌
- Sevilla-Lara et al. (2019)는 표준 데이터 세트의 많은 액션 클래스가 동작 또는 시간 정보를 식별할 필요가 없음을 보여줌. human observer에게는 몇 개의 still 프레임이 충분히 차별적(비디오의 많은 부분을 버릴 수 있음을 의미)
테스트 시간에 계산 비용을 줄이기 위해 사용하는 최근 연구들의 전략 중 하나는 프레임 또는 클립 선택이라는 방법(앞으로는 편하게 프레임 선택이라고 할게요)이다. 매우 성공적이긴 했지만 대부분의 프레임 선택 방법은 action recognition의 특정 domain (즉, 일반적인 길이가 1분 이상인 long, frequently sparse 비디오)에 초점을 맞추었다. 이 domain은 실제로 비디오의 일부를 버리는 것이 더 쉽고 잠재적으로 가장 큰 영향을 미치는 domain이다. 대조적으로, 몇 초의 짧은 비디오에서 프레임 선택 문제는 그 어려움으로 인해 훨씬 덜 탐구된 채로 남아 있다.
이 논문에서는 trimmed 비디오 클립의 core, standard activity classification 설정에서 프레임 선택을 수행하는 방법을 제안
- 이 설정의 문제 중 하나는 “좋은” 프레임이 종종 비디오 내에서 일시적으로 서로 가깝다는 것
- 대부분의 기존 프레임 선택 방법은 프레임을 한 번에 하나씩 선택하는 값을 고려하므로 선택한 프레임은 작업의 일부만 나타내는 경향이 있었다 (프레임의 다양성과 스토리를 전달하는 능력이 무시)
- visual feature와 함께 language feature를 사용하면 성능이 향상된다는 것을 보여줌
이러한 문제를 해결하기 위해 단일 프레임의 차별적 가치를 고려하는 것 외에 비디오에서 다른 프레임과의 관계도 고려하는 모델을 제안
- 프레임의 가치를 함께 조사하는 attention과 relational network(Meng et al. 2019; Sung et al. 2018)를 사용하여 이를 수행
- 우리는 SMART(Multi-frame Attention and Relations in Time) selction 네트워크를 통해 샘플링을 배움
Related Work
Related Work에서는 크게 두 가지로 설명한다. 첫 번째는 Frame Selection이고 두 번째는 Attention and Relational Models다.
####Frame Selection.
행동 인식에서 중요한 프레임을 선택하는 건 새로운 영역의 연구이고 기존의 많이 접근했던 방식으로는 reimforce learning(RL)이고 방식은 밑에 있다.
- 한 번에 한 프레임 씩 검사해서 건너 뛸 수 있는 프레임 수를 예측하는 방식
AdaFrame (Wu et al. 2019c)은 LSTM과 결합하여 RL을 활용
- 프레임이 주어지면 액션 클래스의 예측을 생성하고 다음에 관찰할 프레임을 결정하고 더 많은 프레임을 볼 때 예상되는 보상을 계산
FastFor ward(Fan et al. 2018)는 end-to-end RL 접근 방식
- adaptive stop 네트워크와 fast forward 네트워크의 두 가지 sub 네트워크로 구성
- adaptive stop 네트워크는 프레임 샘플링을 계속하거나 중지할 수 있고, fast forward 네트워크에는 여러 action 집합이 있음(초 단위로 앞 또는 뒤로 이동)
- RL 에이전트는 비디오를 훑어 보는 방법을 학습
FrameGlimpse (Yeung et al. 2016)는 행동 detect가 observation과 refinement에 달려 있다는 직관을 따름
- RNN 기반 agent를 사용하여 다음에 볼(look) 위치를 관찰하고 결정
- 현재 프레임이 주어지면 agent는 신뢰도 점수를 기반으로 예측을 내보낼지도 결정
- agent가 충분히 확신하지 못하면 앞을 내다보기로 결정
MARL(Multi-agent Reinforcement Learning) (Wu et al. 2019a)은 multiple parallel Markov dicision processes를 공식화
- 프레임 샘플링 절차를 초기 샘플링을 점진적으로 조정하여 프레임을 선택하는 것을 목표
- 주변 agent 간의 context 정보와 특정 agent의 과거 상태를 공동으로 모델링하는 context-aware observation 네트워크 존재
- 미리 정의된 action space에 대한 확률 분포를 생성하는 policy 네트워크 존재
SCSampler (Korbar, Tran 및 Torresani 2019)는 긴 비디오에서 가장 두드러진 시간 클립을 효율적으로 얻을 수있는 lightweight clip-sampler
- 압축된 비디오와 비디오에서 얻은 오디오에서 직접 기능을 샘플링
Attention aware sampling (AAS) (Dong, Zhang 및 Tan 2019)은 주의를 사용하여 관련없는 프레임을 삭제하는 agent를 사용
- 프레임 선택 절차를 Markov decision process로 간주하고 심층 강화 학습을 통해 추가 레이블없이 agent를 교육
이러한 모든 접근 방식은 훌륭한 결과를 보여 주었지만 대부분 트리밍되지 않은 비디오 시나리오에 초점. 그러나 untrimmed 비디오에는 불필요한 데이터의 상당 부분이 포함되어 있으며 이를 버리는 것이 timmed 비디오에서 프레임을 버리는 것보다 쉽다. 이전 작업과 달리 프레임을 한 번에 하나씩 고려하여 선택하는 대신 공동으로 고려하는 방법을 제안한다.
Attention and Related Models.
Attention의 개념은 Bahdanau, Cho, Bengio (2014)가 machine translation을 목적으로 도입했다. Attention의 개념은 신경망이 시퀀스 또는 이미지 영역에서 원하는 출력 상태와 관련하여 서로 다른 샘플이 얼마나 관련이 있는지 학습한다는 개념을 기반으로 한다. 이러한 importance value는 attention weight로 지정되며 일반적으로 특정 goal를 위해 학습된 다른 모델 parameter와 동시에 계산된다.
관련 방법들은 논문 참고하시길 바랍니다.
Relation-net(Sung et al. 2018)에서 영감을 받아 얼굴 감정 인식 작업을 처리하기 위해 related attention이 제안되었다(Meng et al. 2019). local level representation과 더불어 feature의 globel level representation이 더 나은 결과를 얻는 데 도움이 된다고 믿었다. 따라서 SMART 논문에서는 temporal attention에 global representation을 추가하기 위해 attention-temporal attention을 추가하는 방식을 사용했다.
SMART Frame Selection
제안된 접근 방식은 최상의 프레임을 선택하는 데 전체 계산 비용의 작은 부분을 사용하도록 설계. 이러한 프레임은 계산 비용이 더 많이 드는 모델을 사용하여 분류. 따라서 SMART 프레임 선택 모델에 대한 입력으로 프레임의 매우 가벼운 표현을 사용.
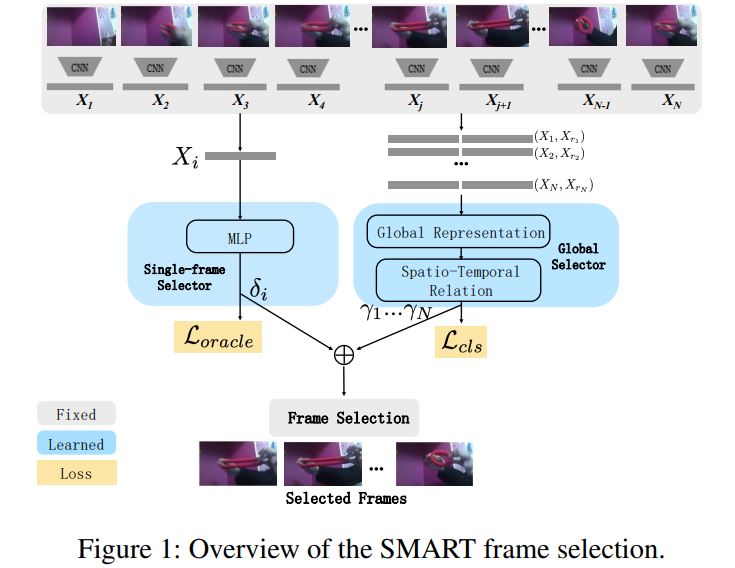
모델은 두 개의 스트림으로 구성
- 첫 번째는 프레임 정보를 한 번에 하나씩 고려하여 각 프레임에 대한 점수 $δ_{i}$ 를 출력하여 프레임이 분류에 얼마나 유용한 지 나타냄.
- 두 번째 스트림은 한 번에 전체 비디오를 고려.
프레임의 입력 쌍으로 취하고 attention and relational 네트워크를 사용하여 이러한 프레임 쌍이 얼마나 유용한 지에 대한 점수 γi를 얻음. 그런 다음 두 점수를 곱하여 각 프레임이 얼마나 좋은지 최종 점수를 얻음. n 프레임의 budget이 주어지면 이제 discriminative score가 가장 높은 상위 n 프레임을 선택하고 최종 예측을 위해 expensive, high quality classifier를 사용. 방법은 Fig. 1에서 볼 수 있다. 아래는 각 구성 요소에 대해 자세히 설명.
Feature Representation
계산 비용을 최소화하고 각 프레임의 시각적 feature를 추출하기 위해 lightweight MobileNet을 선택. 또한 시각적 feature 외에 프레임 내용과 관련된 language feature를 사용할 수 있음을 관찰하도록 함. 이러한 직관은 이미지의 content와 관련된 용어로 feature를 풍부하게하는 것임.
- “카약”과 같은 액션 클래스의 경우 물, 보트, 패들과 같은 관련 단어를 사용하면 카약이 시각적으로 뚜렷하지 않더라도 차별에 도움이 될 수 있다고 상상할 수 있음
이미지와 관련된 language feature를 frame에 포함시킨다. 순서는 아래와 같음
-
- 프레임에서 Imagenet에 대해 pre-training된 Mobilenet을 실행하고 확률이 가장 높은 top 10개의 Imagenet class를 취함
-
- 이러한 class의 이름은 GloVe(Pennington, Socher, Manning. 2014)와 함께 포함되며 10개 class에 대한 평균을 냄
-
- language embedding을 시각적 feature와 concat 후 각 프레임 i에 대한 feature vector $X_{i}$ 가 생성
Single-frames Selector
이 스트림은 매우 빠르게 설계됨. 우리는 expensive 네트워크의 prediction을 보고 Ground Truth class에 대해 가장 높은 신뢰도를 가진 프레임을 선택하는 oracle이 실제로 prediction을 위해 전체 비디오를 사용하는 것보다 성능이 뛰어나다. 따라서 우리는 feature vector $X_{i}$ 를 input으로 취하고 Ground Truth에 대한 분류의 confidence를 계산하는 간단한 MLP를 사용. 이 MLP에는 2개의 layer가 있으며 앞에서 언급한 oracle을 사용하여 학습. 여기서 각 프레임은 Ground Truth class에 대한 해당 프레임의 확률을 출력. 학습 시간에 우리가 보고있는 데이터 세트에서 학습된 expensive 모델을 사용하여 각 프레임의 ground truth 확률을 얻을 수 있다. 테스트 시간에 $δ_{i}$ 는 특정 프레임의 importance score로 학습된 모델에 의해 예측된다.
Global Selector
Multi-frame discriminator는 선택을 위해 프레임 간의 정보를 사용하도록 설계.
-
- 전체 비디오에 attention 모델을 사용하여 비디오의 global Representation을 가져 오는 방식으로 수행.
-
- global Representation이 주어지면 relational 모델과 LSTM 네트워크를 통해 프레임 간의 시간 관계를 학습 이 네트워크는 가볍고 학습하기 쉽지만, 전체적으로 고려할 때 프레임이 얼마나 유용한 지에 대한 정보를 제공한다.
- global selector는 relational 모델을 사용하여 전체 비디오에 대한 프레임 간의 temporal relationship을 학습하여 비디오의 inexpensive global representation을 생성
Pairs of frames.
input sequence $X_{i}$ = ( $X_{1}, … , X_{N}$ )이라고 할 때, $X_{i}$ 는 N개의 total frame 중에서 i번째 프레임의 concatenated visual과 categorical feature를 의미한다고 하자. 그리고 각 프레임에서 랜덤으로 r 번째 프레임을 선택해 concate을 한 것을 $X^{i}{r}$ 이라고 하자. 랜덤 프레임은 action에서 발생하는 일시적인 변화를 캡처하기 위해 항상 이후 프레임 세트에서 선택된다. 일부 action은 이러한 프레임 쌍이 몇 프레임 떨어져 있을 때 가장 잘 인식되고 다른 action은 더 멀리 떨어져 있을 때 더 잘 인식된다. 이 무작위 선택을 통해 모델은 유연하고 다양한 클래스의 시간적 변화를 캡처할 수 있다. Attention 모델에 대한 입력은 두 벡터 $Z{i}$ = $[X_{i} : X^{i}{r}]$ 의 연결이다. 네트워크의 출력은 temporal relation-attention weight $γ{1}, γ_{2}, .., γ_{N}$ 세트다. 이것은 모델이 시간 정보를 얻는 데 도움이 된다.
Attention Module.
coarse self-attention weights $α_{i}$ 는 먼저 FC layer와 sigmoid function을 사용하여 계산된다(Meng et al. 2019). 수학적 표현은 식 1에 나와있다. U는 네트워크 parameter다. 이제 이러한 self-attention weights를 사용하여 input feature를 aggreate한다. 식 1의 $Z^{‘}$ 는 프레임 feature의 global representation다.
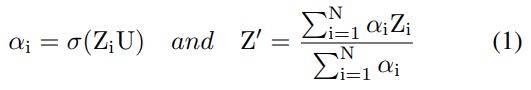
Relation Module.
Sample concatenation과 또 다른 FC layer(Sung et al. 2018)를 추가하여 relation-attention weight $β$ 를 estimate할 수 있다. $Θ^{1}$ 은 FC layer의 parameter고 $σ$ 는 sigmoid function을 나타낸다. 이를 사용하여 frame attention weight를 얻는다. 그러나 temporal attention weight도 필요하므로, LSTM을 사용하여 sequential per frame changes를 캡처한다. 각 time step에서 LSTM의 input은 relational self-attention weight ‘ $ω_{t}$ ‘를 사용한 dynamic weight의 합이다. 이는 식 2에 표시된다.
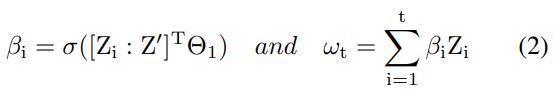
temporal attention weight는 아래 식 3과 4와 같이 계산된다. LSTM의 이전 time step output과 해당 time step의 input에 따라 다르다. b는 bias vector다.
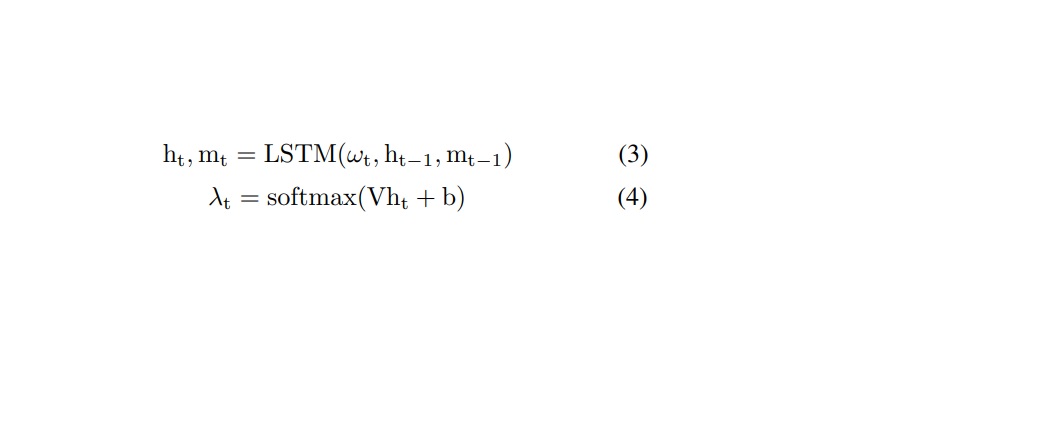
Related-temporal weight를 계산하기 위해, 아래 식처럼 relational-frame attention weight를 얻는다. $Θ^{2}$ 는 네트워크 파라미터다.
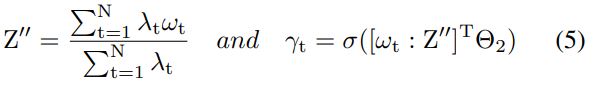
이 γt를 사용하여 식 6에서 시간 ‘t’에서 attend content vector $c_{t}$ 를 얻을 수 있다. 여기서 $h_{i}$ 는 $i$ 에서 LSTM의 hidden state를 나타낸다. classification을 위해, $c_{t}$ 는 예측 레이블 y를 생성하기 위해 MLP에 입력된다. 전체적으로, 이 모듈은 정답 레이블 $yˆ{t}$ 가 주어지면 식 7에 설명된 Loss $L_{cls}$ 를 최소화하는 것을 목표로 한다. 모든 attention weight와 intermediary를 계산하는 단계는 그림 2에서 볼 수 있다.

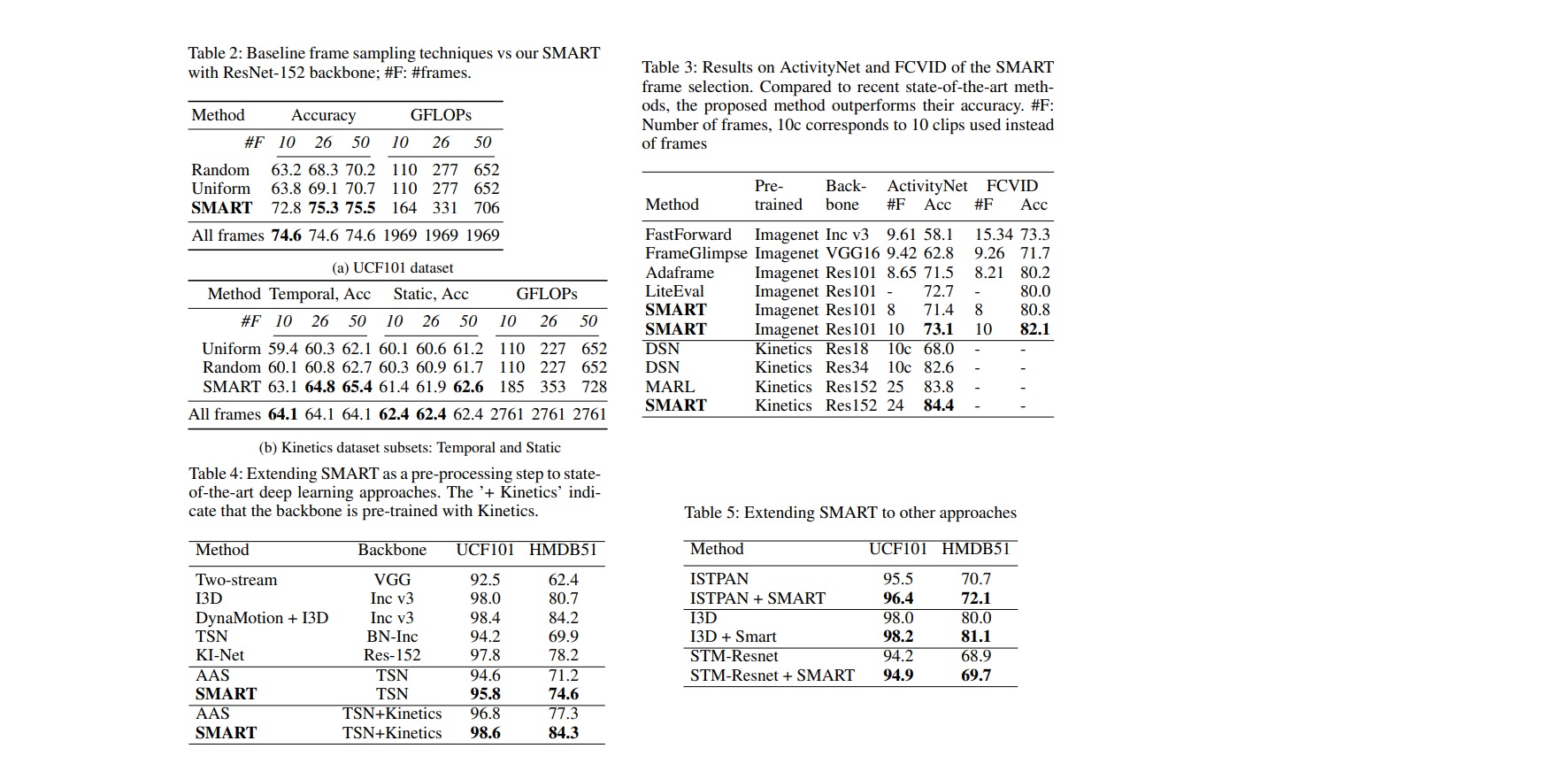
Experimental Analysis & Quantitative results analysis
다양한 실험을 했과 세부 사항들 논문 참고.
Conclusion
- SMART 프레임 선택이라고 하는 트리밍된 비디오 영역에서 프레임 선택을 위한 방법을 제안
- 개별적이 아닌 한 번에 비디오의 모든 프레임을 고려하여 전체적으로 결정을 내리는 문제를 해결
- 3개의 서로 다른 행동 분류 데이터셋에서 기준선의 정확도를 능가하는 반면, 계산 비용을 최대 4배까지 절감
- 정확도 면에서 트리밍되지 않은 비디오에 대한 최근 프레임 선택 방식을 능가
- 2개의 벤치마크에서 최첨단 정확도를 얻기 위한 전처리 단계로 확장될 수 있음
Potential Ethical Impact
이 작업은 비디오에서 효율적이고 효과적인 인식에 관한 것으로 다른 비디오 인식 모델과 이점 및 우려 사항을 공유한다. 비디오의 콘텐츠를 더 효과적으로 인식할 수 있다는 것은 accessing video(검색)할 때 사용자에게 잠재적으로 긍정적인 영향을 줄 수 있다. 또한 이 작업에서 이러한 종류의 데이터를 실험하지는 않지만 harmful content를 보다 효과적으로 제거할 수 있다. 그러나 그러한 사용 사례를 추구하기 전에 모델을 훈련하는 동안 얻거나 우리의 접근 방식이 사용하는 pre-trained 모델에서 상속된 잠재적인 알고리즘 편향에 대해 모델을 분석하는 것이 중요하다.
Leave a comment