3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection 리뷰
Updated:
3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection 정리하기
논문
https://arxiv.org/abs/2004.12636
저자 정리
https://yckim.medium.com/3d-cvf-generating-joint-camera-and-lidar-features-using-cross-view-spatial-feature-fusion-for-3d-5a99ab93a558
github
https://github.com/rasd3/3D-CVF
Introduction
Camera-LiDAR Sensor Fusion 네트워크 제안 계기는 아래와 같음
- 라이다 데이터는 강력한 정보는 맞지만 거리에 취약함(거리가 멀수록 sparse)
- Camera는 dense하고 texture 정보가 강하기 떄문에 장단점을 보완할 수 있을 것
하지만 위처럼 동시에 사용하는 논문 중 최근 상위 랭크의 논문들은 없었음. 이유는 뭘까?
- 라이다 정보가 매우 강력하여 다른 센서의 데이터 중요도가 떨어짐
- 다른 센서 데이터 사용하여 라이다 align 후 feature를 concat해도 네트워크는 다른 센서 데이터를 사용하지 않기 때문에 결국 안쓰느니만 못한 결과 얻음
본 저자의 focus : 어떻게 하면 카메라 데이터를 라이다 데이터가 부족한 곳에 상호보완적으로 작용시킬 수 있을까.!
결과적으로, adaptive gated fusion network를 통해 라이다 데이터로만 검출하기 어려운 부분을 카메라 데이터로 보완할 수 있는 부분이 어딘지 스스로 학습하고, 추가적인 fusion을 통해 라이다 단점을 보완하여 성능 상승!
라이다 좌표계 기반의 fusion feature를 얻기 위해서 1차적으로 camera feature를 auto-calibrated feature projection을 사용해 라이다 도메인으로 projection시킴. 이후 spatial-attention 기반의 adaptive gated fusion network를 통과시켜 LiDAR feature와 융합시킴!

여기서 나온 fusion feature를 통해 1차적으로 물체를 검출하고 이를 3D ROI Fusion-based Refinement 모듈에 넣어 refine시키는 구조를 가지고 있음. refinement 모듈에서는 1차 검출 박스에 기반하여 fusion feature, camera feature, LiDAR feature 3가지의 feature에서 각각 ROI align, ROI-based pooling, ROI Grid-based pooling을 이용해 융합시킨 후 최종적으로 물체를 검출!
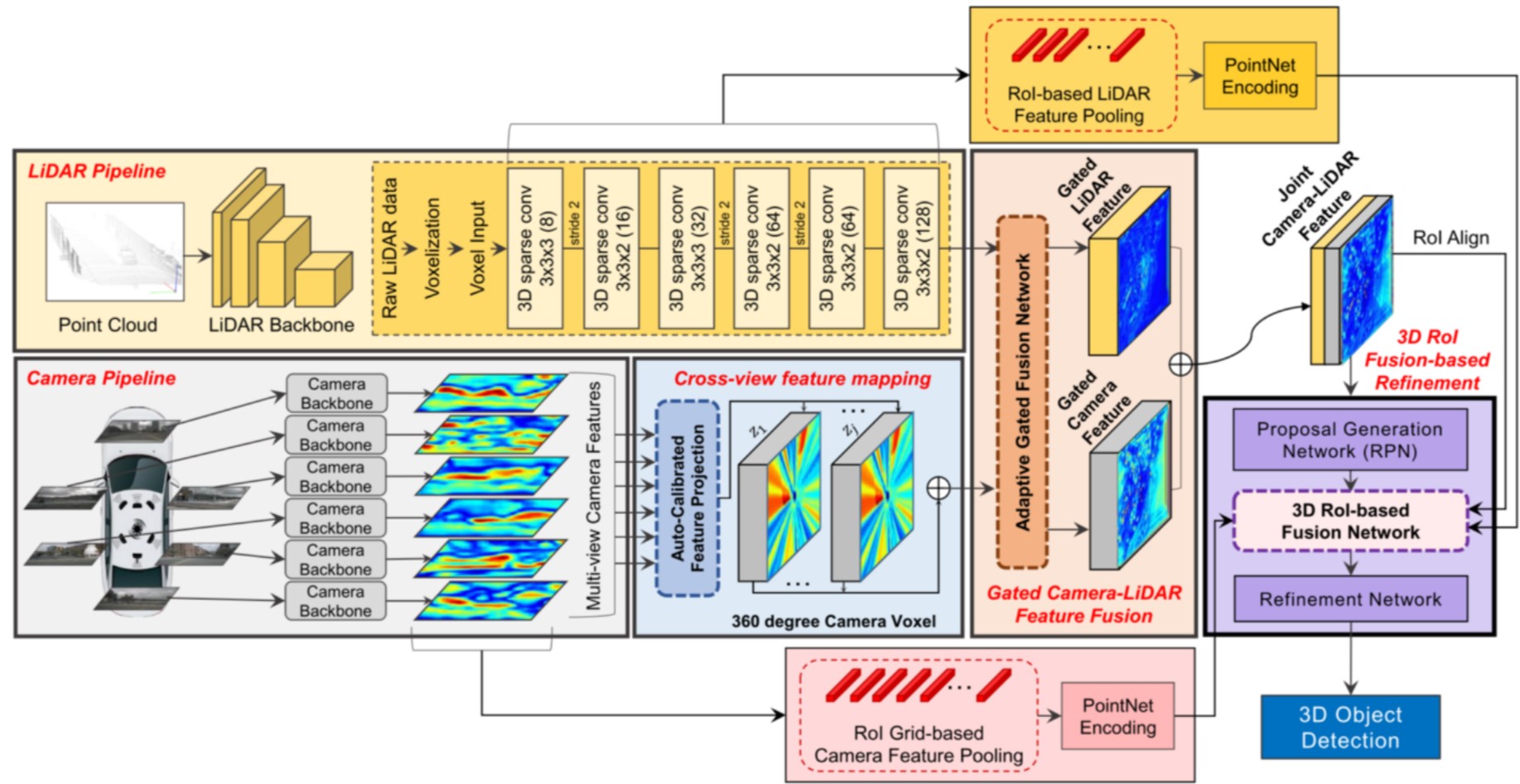
Network
LiDAR pipeline은 SECOND 구조를 사용, camera pipeline은 KITTI 2D object detection task를 위해서 pre-train된 FPN18구조를 사용
Cross-View Feature Mapping
Auto-Calibrated Projection Method
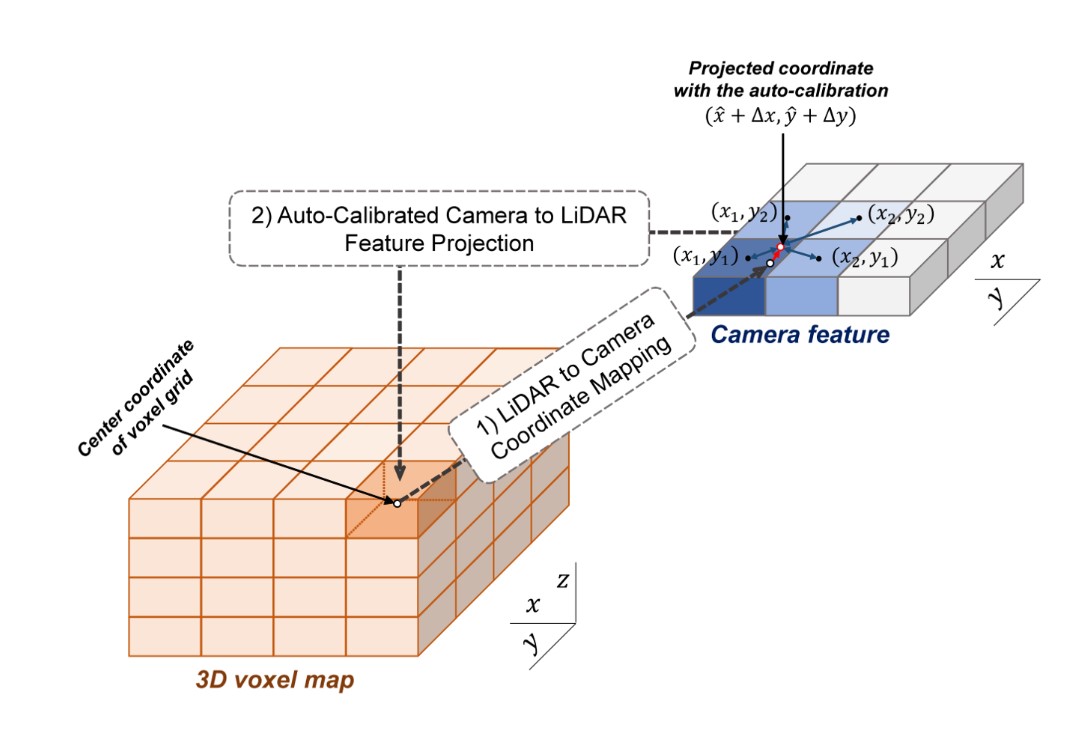
보통 camera feature를 라이다 좌표계로 projection하면 라이다 좌표계에서의 3D voxel map을 설정하고 각 voxel의 중심 좌표를 카메라 좌표계로 정사영시킨 후 해당되는 camera feature를 가져와 voxel에 할당하는 방식으로 이루어졌음.
- 위 방식의 문제점은, interpolation을 수행하지 않았기 때문에 discrete한 feature가 얻어지며 noise가 있을 수 있는 calibration matrix의 성능에 의존한다는 것
이 부분을 네트워크가 학습할 수 있도록 저자는 voxel의 중심 좌표를 정사영한 카메라 좌표계에서 주변 4개의 픽셀을 얼만큼의 비율로 interpolation할지를 학습하는 Auto-Calibrated Projection Method를 제안함. 이 방법으로 information fusion에 용이하고, 비교적 continuous한 fusion feature를 얻을 수 있게 됨!
Adaptive Gated Fusion Network
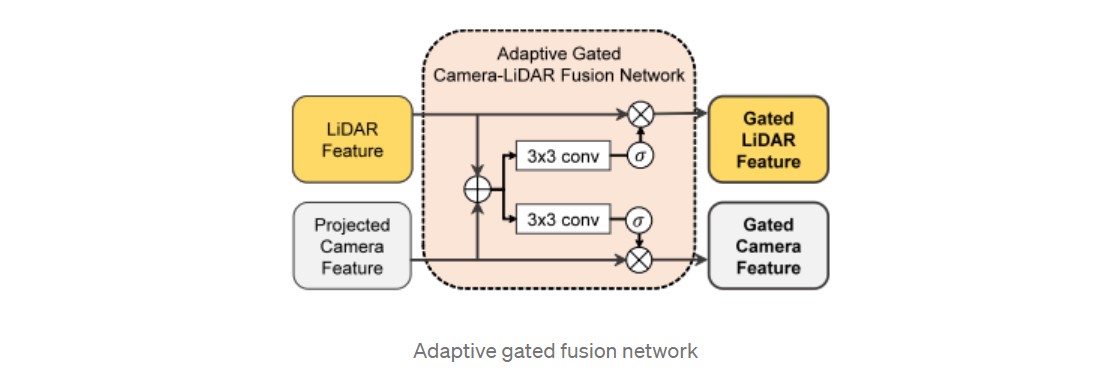
Introduction에서 언급했듯이, 라이다 데이터의 중요도가 매우 높아 단순히 camera feature를 concat하면 안 쓰느니만 못한 결과를 얻음. 하지만 라이다는 거리가 멀면 sparse해지므로 이를 camera feature가 도움을 줄 수 있는 부분을 고민해본 결과 Adaptive Gated Fusion Network를 사용하게 됨.
라이다 feature와 카메라 feature를 입력으로 각 feature를 강화시키는 spatial attention map을 만들어 각 feature에 pixel-wise multiplication을 해주는 구조로 구성되어있다. 이렇게 되면 각 센서 feature의 필요한 부분만 남기고 불필요한 부분은 없어지게 됨!
맨 위그림을 보면 (b) 형태를 가지고 있는 projected camera feature가 Adaptive Gated Fusion Network를 통과하게 되면 (c) 형태가 된다. 라이다 데이터를 보고 카메라 feature에서 어디가 필요한지를 보고, 빨간색으로 활성화된 부분은 물체 검출을 위해 필요하다고 스스로 학습하여 남기게 된다.
결과적으로 Gated Lidar feature와 gated projected camera feature를 얻게 되고 이를 concat한 Joint Camera-LiDAR feature를 입력으로 1차 결과를 뽑음!
3D-ROI Fusion-based Refinement Region
Region Proposal Generation
일반적인 RPN 모델과 동일하게 작동. 본 논문에서의 입출력은 아래와 같이 동작한다.
- 입력 : Joint Camera-LiDAR Feature
- 출력 : bounding box의 위치정보, confidence
이 중 높은 confidence를 기준으로 sort한 후 NMS를 적용하여 남은 proposal을 refinement network에 전달해준다.
3D ROI-based Feature Fusion
예측한 box의 좌표에 근거하여 rotated 3D ROI alignment를 이용해 Joint Camera-LiDAR feature에서 각도 정보와 3차원 좌표를 이용하여 필요한 정보를 crop한다.
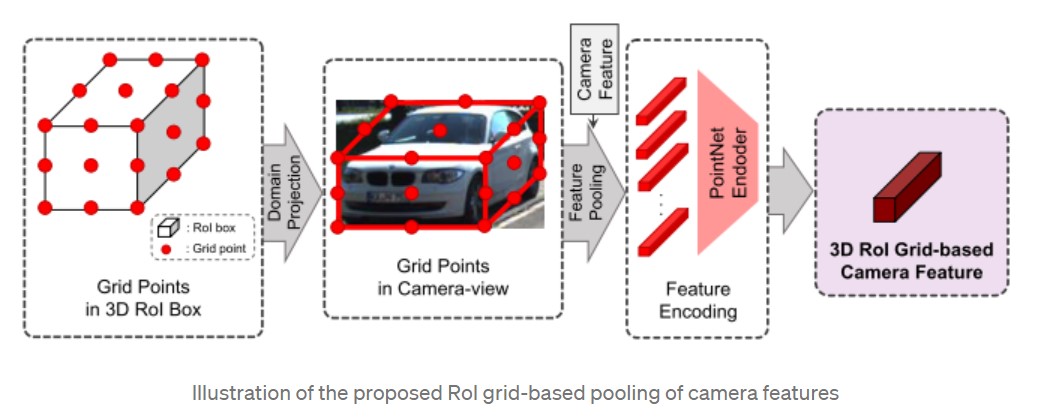
동시에 예측한 bounding box 정보를 기반으로 카메라 정보를 추가적으로 이용하기 위한 ROI grid-based pooling 방법을 제안하였음. 동작은 아래와 같다.
- 예측한 bounding box를 균등하게 r x r x r의 grid로 나눈 후 각 grid point를 camera 좌표계로 projection한 다.
- 이후 해당되는 camera feature를 grid point로 다시 가져온다.
- PointNet 기반의 encoder를 사용해 3D ROI Grid-based Camera Feature를 만들게 되고 이를 rotated 3D ROI alignment한 feature와 같이 이용한다.
- 이를 통해 z축까지 반영된 camera feature를 최종 결과에 이용할 수 있게 하였음
Training Loss Function
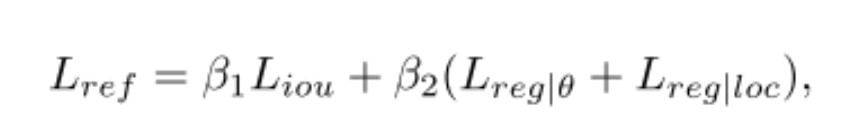
기존 네트워크의 loss에서 3D IoU loss를 추가한 형태이다. confidence만으로 예측한 bounding box의 정확도를 정확하게 예측하기 힘들다고 판단하여 다양한 3D object detector에서 사용된 loss이다. 예측한 box와 GT의 3D IoU를 계산하고 이를 loss target으로 잡아 confidence가 높지만 IoU가 작은 bounding box에 대해 loss를 부과하는 구조이며, 큰 성능 향상을 가져온다.
Leave a comment