An Improved two-stream 3D convolution Neural Network for Human Action Recognition 리뷰
Updated:
An Improved two-stream 3D convolution Neural Network for Human Action Recognition 리뷰
논문 내용 정리하였습니다.
논문 다운 링크
https://ieeexplore.ieee.org/abstract/document/8894962
Abstract
- Spatiotemporal Two-stream Neural Network Architecture 제안
- Camera 움직임이 많고 장면이 많이 바뀌는 Video에서 global context information을 정확하게 얻을 수 있음
- 개선 사항
- ResNet-101을 Two-stream에 independent하게 통합
- 각 stream의 Conv layer에서 얻어진 2가지 Feature map을 서로 fuse
- 3D CNN을 사용하여 Temporal information과 Spatial information을 결합
- 더 많은 Latent information을 뽑을 수 있음
- 사용한 Dataset
- UCF-101
- HMDB51
- Keywords : Optical Flow, Human Action Recognition, Two-stream CNN, Three-dimensional CNN
Introduction
- Human Action Recognition은 video에서 Human Activity를 이해하고 연구하기 위해 개발됨
- 최근 CNN 기법들이 Image classification application에서 성공적인 결과를 얻었기 때문에 video-based action classification에서도 CNN으로의 접근을 많이 시도중임
- 이전의 방식들
- The handcrafted extraction
- 3D-HUG, IDT, MBH 등
- Deep learning
- CNN 기반 two-stream
- The handcrafted extraction
- Optical Flow
- Video 분석에서 motion 정보를 표현하는 효과적인 표현
- CNN 학습에서 폭 넓게 사용 됨(2-stream CNN, 3D CNN)
- Dense optical flow extraction은 많은 시간을 소요하기 때문에 OFF(Optical Flow guided Feature) 방식이 나옴
- OFF는 효율은 좋지만 주요 static information extraction은 소실
- 현재 Human Action Recognition의 문제들
- 고전적인 handcrafted feature들은 많은 계산량을 요구하기 때문에 real-time 불가
- 최근 Deep Learning 방식들은 대략적인 motion feature만 결합하기 때문에 주요 정보 소실 가능성이 있음
- 순수 3D CNN은 좋은 recognition rate를 얻는데 실패
Improved Two-stream Network Structure
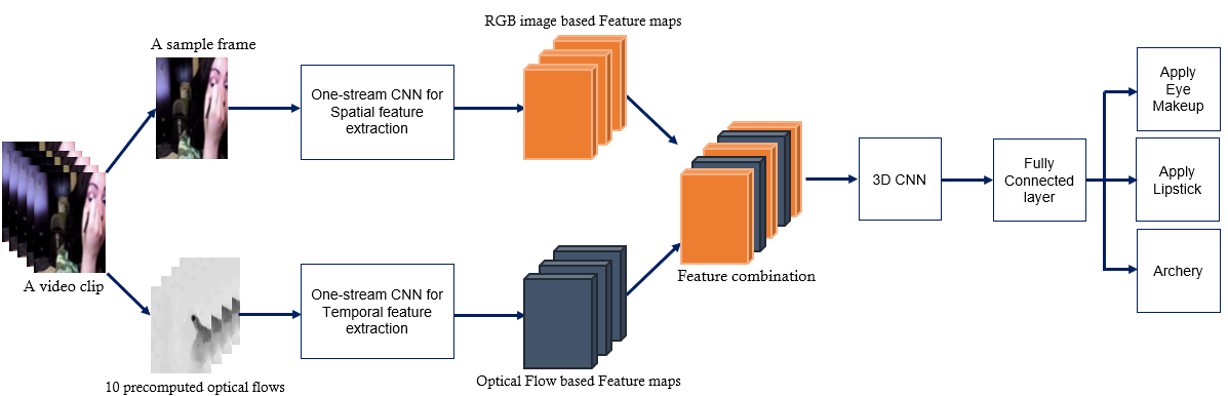
- Video clip은 spatial & temporal feature로 자연스럽게 표현 가능
- Sptial : 장면의 모양과 object 정보를 전달하는 single frame으로 표현
- Temporal : object의 움직임 상태를 전달
- 독립적인 model 2개를 각 RGB랑 Optical Flow로 동시 학습
- Two-stream에서 나온 결과는 softmax layer에서 fuse
- Fig.1 : 제안한 방법의 타당성과 효과 입증
- Optical flow는 motion 정보를 효과적으로 표현
- 서로 다른 시간의 optical flow와 RGB image가 중첩되어 보다 포괄적인 motion 정보 생성
- 3D CNN은 시공간적인 특징을 기반으로 풍부한 의미를 추출할 수 있어서 global contextual information 활용에 좋은 recognition rate를 가질 수 있음
- A. Optical Flow Extraction
- Temporal feature를 추출하기 위한 stream의 입력으로 들어감
- Dense optical flow는 DOF field를 형성하기 위해 image의 모든 점에서 offset을 계산을 통해 이미지에 대한 점 단위 일치를 위한 영상 정합 방법 –> 이렇게 생성된 DOF field로 픽셀 수준의 영상 정합 가능
- Dense optical stream은 t frame과 t+1 frame 사이에 있는 변위 벡터 field set
- 변위 벡터 $d_{t}(u,v)$ : t frame, 위치 (u,v). $d_{t}^{x}, d_{t}^{y}$ 는 vector field의 수평, 수직 부분을 나타냄
- 연속된 일련의 frame들 사이의 motion을 표현하기 위해, 본 논문의 연구에서는 L개의 연속 frame에서 optical flow channel을 쌓아 2L의 input channel 길이를 형성
- 모든 pixel 포인트에 대해 채널 $I_{t}(u, v, c)$ 는 L개의 연속 frame을 통해 해당 pixel에 대한 motion 정보를 인코딩 (c = 2L)

- B. RGB and Optical Flow Feature Fusion
- Optical flow를 추출한 후에 ImageNet dataset으로 pre-trained된 two-stream CNN 학습
- Two-stream network는 ResNet-101 network를 사용
- 왜 ResNet을 사용했는가?
- H(x) = F(x) + x -> 학습의 복잡성을 단순화하며 정확도를 상승시킴
- Image feature 뽑는데 좋은 성능을 보여주었고, Ultra-deep 신경망 학습 속도를 가속화시킴
- Table 1에 Network 비교 (ResNet-101과 ResNet-34 비교)
- 왜 ResNet을 사용했는가?
- Pixel intensity에서만 contextual 정보를 결정하는 것은 매우 어려워서 RGB와 Optical flow를 모두 사용
- Spatial feature 추출은 RGB images에서 temporal feature를 추출하기 위해서는 서로 다른 순간에 해당하는 10개의 optical flow를 사용
- RGB image는 7x7x256 volume data가 됨
- 10개의 미리 계산된 optical flow를 처리하기 위해 각 10개의 x-channel, y-channel이 있음
- 그 후 RGB feature map을 10개 복사해서 각 optical flow feature map과 매칭
- 20개의 output channel 생성
- Matching module 은 RGB와 optical flow 사이의 관계를 파악하여 결합된 contextual information을 추출
- 결합된 모든 feature map은 그 뒤에 오는 3D CNN을 사용하여 spatial과 temporal dimension 을 모두 convolution
- RGB image는 7x7x256 volume data가 됨
- C. 3D CNN For Convolution Operation
- Video에서 motion 정보를 효과적으로 capture하기 위해 3D convolution이 고안
- 3D CNN은 Spatial과 Temporal 정보를 모두 동시에 capture할 수 있으므로 추출된 feature는 action classification에서 더 차별적
- 이전의 two-stream의 feature map을 최대한 활용하기 위해 3D CNN 사용
- 3D CNN을 사용해서 combined feature map에서 convolution 연산 수행하여 시공간 차원에서 구별되는 특성 캡쳐
- 3D CNN 입력은 X_t∈R^HxWxTxD (결합된 feature map 쌍)
- 논문에서는
- y = X_t * f + b
- f = 3D convolution kernel
- b = bias
- kernel size = 3 x 3 x 3 x 2n
- y = X_t * f + b
Experimental Results And Evaluations
- Dataset
- UCF-101
- HMDB51
- Network Training
- Pytorch 구현
- 각 stream은 imageNet으로 학습한 Resnet-101을 사용
- global average pooling method
- RELU activation function
- 각 Convolution Layer 이후에 Local Response Normalization layer 추가
- batch size = 64
- learning rate = 0.01
- dropout 사용 대신 weight attenuation을 0.0001, momentum을 0.9 사용
- Experimental Result Analysis

- Table 2.
- ImageNet pre-training two-stream과 pre-training하지 않은 two-stream 성능 비교
- pre-training을 사용한 것이 성능이 높음
- pre-training이 CNN 초기화에 효과적인 방법임을 입증
- Layer가 더 많으므로 ResNet-101이 ResNet-34보다 Recognition rate가 더 높음
- 전체적 2-stream 3D CNN의 human action recognition rate가 single-stream CNN보다 증가

- table 3.
- 다른 sota handcrafted & classic 2-stream CNN 접근들과의 비교 (iDT, iDT+HDE, …)
- 측정은 average recognition rate
- dataset은 UCF-101에서 89.1%, HMDB51에서 62.1%를 기록
- Experimental Result Analysis
- Contributes
- 2-stream CNN 개선
- 10개의 연속적인 순간에 대해 optical flow와 2-stream CNN의 마지막 layer에 RGB image 정보의 조합을 제공
- Video frame에서 더 많은 motion 및 contextual 정보를 얻을 수 있음
- 마지막의 3D CNN은 combined feature map pair들을 더 fuse하여 전체 video clip의 motion 정보를 완전히 표현하는 효과적인 feature 추출
- Contributes
Conclusion And Future Work
- Conclusion
- 새로운 Spatiotemporal 2-stream 3D CNN 구조 제안
- 보다 포괄적인 motion 정보를 얻을 수 있으므로, video-based human action recognition에 2-stream 3D CNN이 더 적합
- 3D CNN을 수행하면 인접 frame에 따라 여러 정보 layer가 생성되고 해당 정보는 2-stream의 특징 추출을 위한 입력으로 제공
- 실험 결과, Spatial과 temporal stream 사이의 특징 상관을 학습하는 것이 매우 중요하다는 것을 증명
- 새로운 Spatiotemporal 2-stream 3D CNN 구조 제안
- Future Work
- Feature fusion method를 개선함으로써 학습 시간을 줄여야 함
Leave a comment