Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition 리뷰
Updated:
Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition 리뷰
논문 내용 정리하였습니다.
논문 및 Github 링크
https://arxiv.org/pdf/2008.01232.pdf
github.com/artest08/LateTemporalModeling3DCNN.git
Abstract
3D convolution with late temporal modeling for action recognition 제안을 했다. 큰 특징은 Temporal information을 더 잘 활용하기 위해서 3D CNN의 끝의 Temporal Global Average Pooling (TGAP)을 BERT로 교체한다. 그 결과 많은 action recognition의 3D convolution architecture에서 좋은 성능을 보여주었다. 그 결과, UCF101에서 98.69%, HMDB51에서 85.1% 달성하며 SOTA를 달성하였다.
Keywords : Action Recognition, Temporal Attention, BERT, Late Temporal Modeling, 3D Convolution
Introduction
Video Clip에는 AR(Action Recognition)에 대한 두 가지 중요한 정보(Spatial & Temporal information)가 포함되어 있다. Spatial information은 static information을 나타내며, Temporal information은 dynamic nature를 capture한다.
이 연구에서는 two temporal modeling concept (3D convolution과 late temporal modeling)에 대해 joint uilization을 제안한다.
3D convolution
- 시작부터 끝까지 계층적으로 temporal relationship을 생성하는 방법
late temporal modeling - 일반적으로 2D architecture에 사용
- 2D architecture로부터 추출된 feature는 recurrent architecture(LSTM, Conv LSTM 등)으로 modeling
위의 이점에도 불구하고 temporal global average pooling (TGAP)의 단점은 아래와 같다.
- final temporal information의 richenss에 방해
- action을 구분함에 있어서,
- 특정 frame이 다른 frame보다 중요할 수 있음
- temporal information을 평균을 취하는 것보다 frame의 순서가 더 중요할 수 있음
그러므로 BERT를 사용함을 제안한다. BERT는 multi-head attention mechanism으로 어떠한 temporal feature가 더 중요한지 결정한다. TGAP을 late temporal modeling로 바꾸는 것과 AR에서 BERT를 사용하는 것은 우리가 최초이다. BERT를 사용해 각 모델(ResNeXt101, I3D, SlowFast, R(2+1)D )들의 3D CNN의 성능을 향상시켰고 그 중 BERT R(2+1)D가 SOTA 달성하였다.
Related Work on Action Recognition
2가지 관점에서 AR을 분석하였다.
- temporal integration using pooling, fusion or recurrent architectures
- 3D CNN architecutres
Temporal Integration Using Pooling, Fusion or Recurrent Architectures
Pooling이란
- various temporal feature들을 combine
- 종류 : concatenation, averagin, maximum, minimum, ROI 등
Fusion은 AR에서 pooling과 매우 유사한 기능으로 사용
- architecture에서 pooling location을 강조
- 다른 modality들로부터 information 구별
Recurrent Network는 일반적으로 시간적 통합에 사용
3D CNN Architectures
3D CNN
- 3D 컨볼루션으로 구성된 네트워크
- filter가 3D로 설계되며 channel과 temproal information은 다른 dimension으로 표시
- 2D architecture에 비해 매우 큰 computational cost와 memory demand가 필요
C3D, I3D, ResNet version of 3D convolution, R(2+1)D S3D CSN, Slow-fast network들에 대해 간단한 설명은 생략하겠습니다..
하지만 이러한 3D CNN의 장점에도 불구하고 architecture의 끝 단에 effective temporal fusion strategy가 여전히 부족
Proposed Meothods
main proposed mothod, novel feature reduction blocks, BERT-based temporal modeling implementations on SlowFast architecture 순서로 설명
BERT-based Temporal Modeling with 3D CNN for Action Recognition
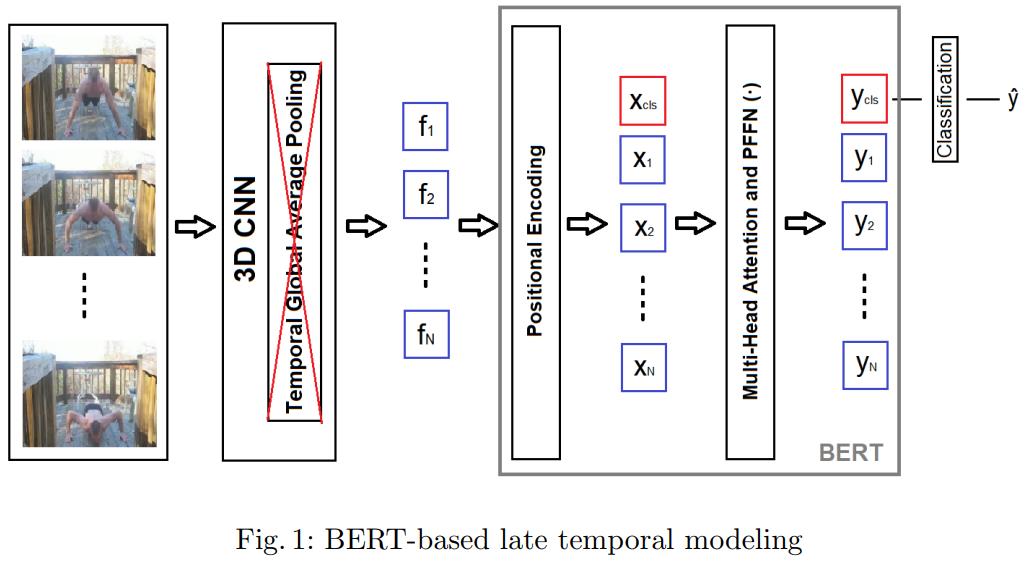
BERT = Bi-directional Encoder Representations from Transformers
- NLP에서 전례없는 성공을 이루어냄
- 양방향으로 context information 융합
- many NLP tasks에서 unsupervised pre-training 도입
Fig.1
- TGAP를 사용하지 않고 BERT를 사용함
- positional information을 보존하기 위해, 추출된 feature에 learned encoding을 추가
transformer 구조에 대해 자세한 설명은 하지 않지만 single head self-attention model of BERT에 대해 설명한다.
식은 다음과 같다.
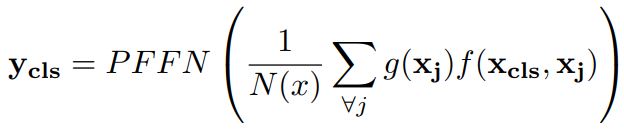
- query : $\theta (x_{i})$ = $x_{i}$ 의 정보 = 앞의 3D CNN에서 뽑은 output에서 i 번째 시간의 feature
- key : $\phi (x_{j})$ = $x_{j}$ 의 정보 = 3D CNN에서 뽑은 output에서 특정 시간의 feature
- $f(\mathbf{x_{i}}, \mathbf{x_{j}}) = softmax_{j}(\theta (\mathbf{x_{i}})^{T}\phi(\mathbf{x_{j}}))$
앞에 sumation이 있으니 모든 시간에 대해 pair로 계산하겠다는 의미이며 다른 말로, 시간 축에 attention을 주겠다는 의미이다. - value : $g(x_{j})$ : $x_{j}$ 의 정보 = 위와 같음
위의 g, $\theta$ , $\phi$ 는 transformer 구조(BERT)처럼 matrix 연산으로 feature vector를 뽑고 논문에서는 이를 linear projection이라고 칭한다. 이 뒤에 FPPN() 연산을 한 것이 결과 $y_{i}$가 된다.
BERT의 temporal attention mechanism 사용의 이점
- learn the convenient subspace
- learn the classification embedding
Non-local Neoural Network 설명 및 proposed BERT attention과의 비교
- non-local NN은 architecture 내부에 넣어지는 것
- proposed BERT attention은 3D CNN에서 추출된 feature에 적용시킨다는 것과 multi-head attention concept을 TJㅓ self-attention mechanism과 multi-relation 생성
- proposed BERT attention은 order information을 보존하고 learnable classification token을 활용하기 위해 positional encoding 활용
이전의 video action transformer network[10]는 주변 video에서 다른 사람과 물체의 contextual information을 수집하기 위해 transformer를 사용한다. 이러한 video action transformer network는 action localization과 action recognition을 모두 다루기 때문에 action recognition만 다루는 우리는 late temporal modeling을 위해 attention mechanism을 다시 구성해야 한다. 이러한 video action transformer network과 달리 우리가 제안한 BERT-based late temporal modeling은 backbone architecture의 ouput의 feature를 pooling하는 대신에 the learnable classification token을 사용한다.
Proposed Feature Reduction Blocks: FRAB & FRMB
새로운 Feature Reducton 제안
BERT를 그냥 쓰기엔 computation complexivity가 매우 크다. output feature의 dimension이 512이면 single-layer BERT의 parameter가 3M, 2048이면 50M의 parameter를 가진다고 한다.
그래서 two feature reduction block을 제안
- Feature Reduction with Modified Block (FRMB)
- Feature Reduction with Additional Block (FRAB)
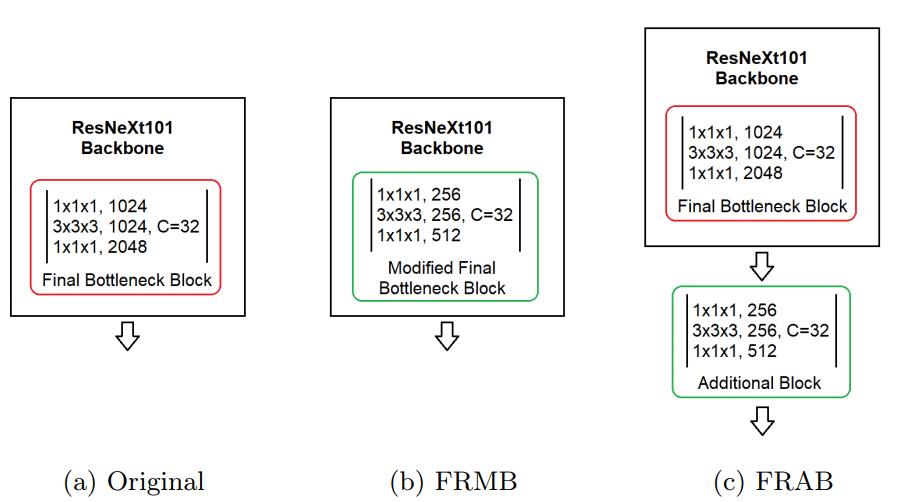
Feature Reduction with Modified Block (FRMB)
- CNN backbone의 마지막 unit block을 novel unit block으로 대체
- FRAB보다 Computational complexity가 낫고 parameter efficiency가 좋다
Feature Reduction with Additional Block (FRAB)
- backbone에 additional unti block 추가
- feature reduction block이 fine-tuning에서만 구현되고 pre-training에서 구현되지 않으면 더 큰 dataset의 pre-trained weight로의 이익을 얻을 수 없음
Proposed BERT Implementations on SlowFast Architecture
다른 3D CNN과 다른 2-stream 구조여서 따로 비교한다고 함. SlowFast 논문을 아직 안읽어봐서 자세한 내용은 잘 모르겠지만 논문에서 나온 내용대로 정리하면…
SlowFast 설명
- slow stream은 더 나은 spatial capability를 가지고
- fast stream은 더 나은 temporal capability를 가짐
- fast stream은 slow stream과 비교해서 temporal resolution이 더 좋고 channel capacity가 더 적음
Temporal resolution이 다르기 때문에 BERT를 구현하기가 불가하다. 따라서 early-fusion BERT와 late-fusion BERT를 제안한다.
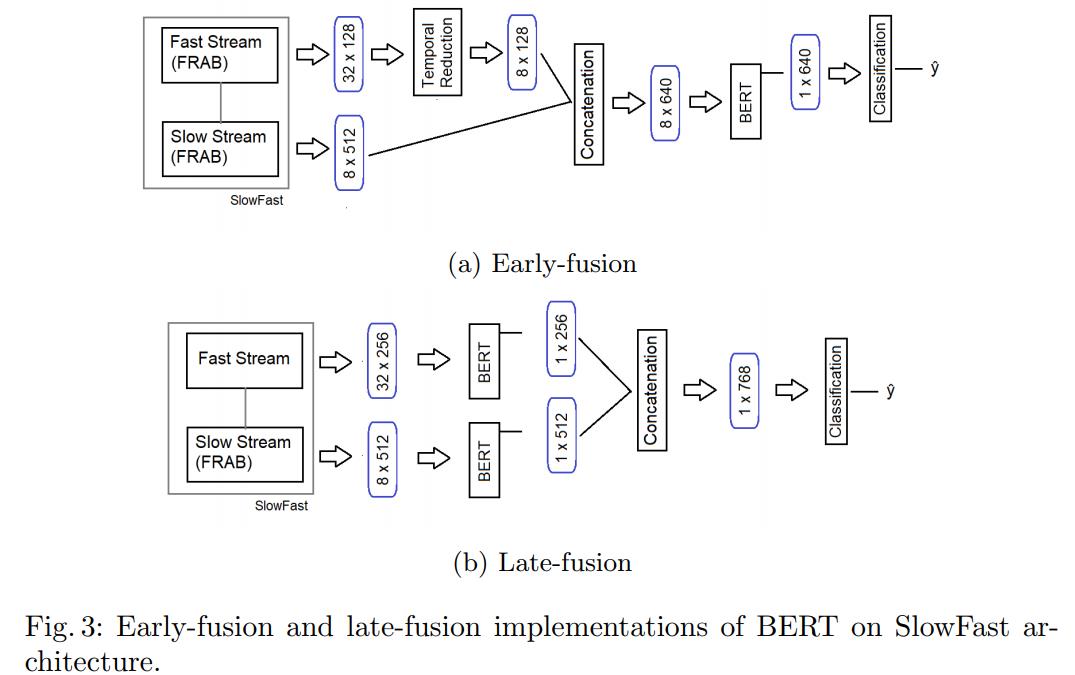
Early-fusion BERT
- Temporal feature가 BERT 이전에 연결
- 단일 module만 사용
- concat이 가능하게 하려고 fast stream의 temporal resolution이 느린 slow stream의 temporal resolution을 감소
Late-fusion BERT
- 각 stream마다 다른 BERT module 사용
- BERT module이 output 연결
Experiments
Dataset
총 4개를 사용하였다. HMDB51, UCF101, Kinetics-400, IG65M
HMDB51
- 51 class
- 7k clip
UCF101
- 101 class
- 13k clip
Kinetics-400
- 400 class
- 240k clip
IG65M
- Kinetics-400의 class 이름들을 인스타그램 해시태그로 사용해서 수집하는 weakly supervised dataset
- 400 class
- 65M clip
- 공개는 하지 않지만 pre-trained weight는 공개
ResNeXt, I3D, Slowfast는 Kientics로 pre-train하고 R(2+1)D는 IG65M으로 pre-train시켰다.
Implementation Details
학습할 때 기존 architecture와 BERT-based architecture의 차이 설명, optical flow는 TV-L1 algorithm으로 사용하고 학습에서 초기화 value 등 자세한 설명이 나와있다. 논문 참고.
Ablation Study
각 단계를 분석하고 제안한 방법과 atternative pooling 방법이 어떻게 비교되는지 (Table 1) 설명
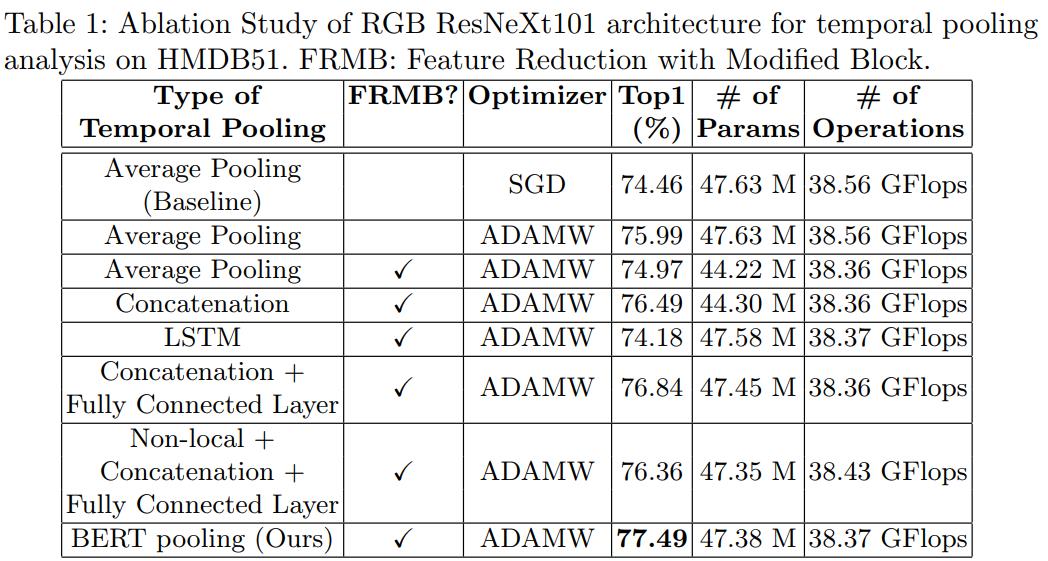
NLP에서 BERT는 Adam을 사용했었다. AR에서 3D CNN은 SGD를 사용하니 BERT는 ADAMW를 사용하였다. ADAMW는 adam의 generalization capability를 향상시킨 것이다.
FRMB를 사용한 이유
- FRAB보다 Top-1 performance가 0.5% 더 좋았음
- FRAB보다 더 좋은 computational complexity와 parameter efficiency를 가짐

BERT layer의 수를 늘리면 성능이 감소하였다. 원인으로 late temporal modeling이 풍부한 언어 정보를 capture하는 것만큼 복잡하지 않고, 단일 layer가 3D CNN architecture의 output feature간의 temporal relation을 capture하기에 충분할 수 있기 때문이라고 저자는 생각한다고 한다.
Results on Different 3D CNN Architectures
3D CNN Architecture에서 TGAP를 BERT pooling으로 바꿔서 얻은 결과를 설명한다. 각 Architecture에 대해 입력 사이즈나 frame length, BERT 사용 유무의 차이점 등 설명을 한다. 굉장히 많은 실험을 한 것이 느껴지니 꼭 논문을 참고하도록 하자. 결과적으로 BERT를 사용한 것이 더 좋았다는 내용이다.
Comparison with State-of-the-Art
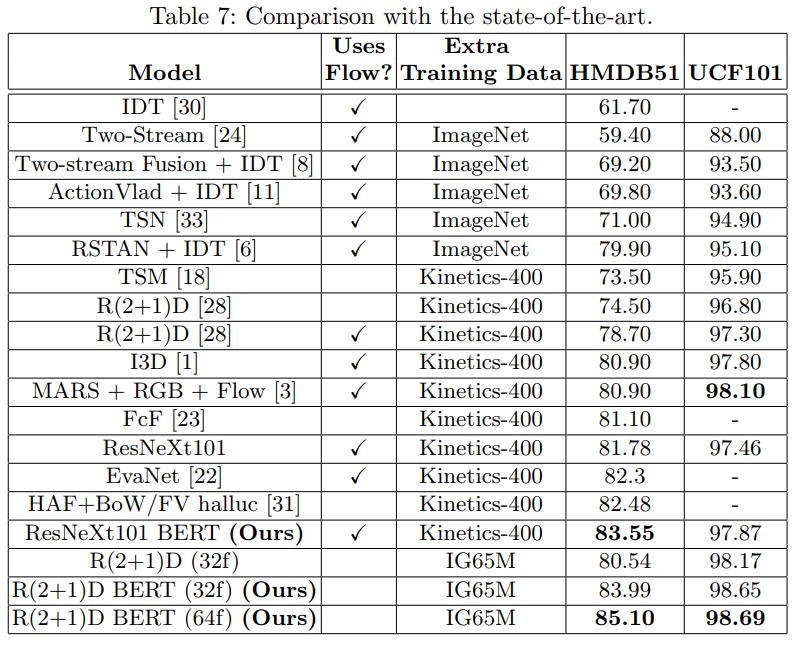
BERT를 사용한 것이 더 좋았고 IG65M dataset에 대해서도 pre-training 효과가 더 있었음을 보여준다.
Conclusions
TGAP를 제거하고 3D architecture의 output에서 temporal information을 더 잘 사용하는 첫 번째 연구임을 시사한다고 말한다.
가능한 연구 방향 제시
- FRMB와 FRAB같은 feature reduction block을 사용하지 않은 parameter efficient BERT 개발 (feature reduction을 하면 최종 추출된 feauture의 dimension이 감소되는 것이니 안 좋은 것일 수 있다)
- BERT의 실제 이점이 unsupervised learning이니만큼 BERT 3D CNN architecture도 여전히 unsupervised 개념을 제안할 수 있다
Potential
- Action Recognition과 유사한 task들을 개선할 수 있는 잠재력을 가짐
Leave a comment