BlazeFace : Sub-millisecond Neural Face Detection on Mobile GPUs 리뷰
Updated:
BlazeFace : Sub-millisecond Neural Face Detection on Mobile GPUs 리뷰
Google Research 에서 나온 논문이고 현재 아카이브에만 등록되어있습니다.
논문 다운 링크
https://arxiv.org/abs/1907.05047
Abstract
모바일 GPU 추론에 최적화된 가볍고 성능 좋은 face detector BlazeFace 소개
- Flagship devices 에서 200~1000+ FPS의 속도
이 super-realtime performance 를 통해 task-specific model 에 대한 입력으로 정확한 관심 얼굴 영역이 필요한 모든 augmented reality pipeline 에 적용할 수 있음
- Task-specific model 예 : 2D/3D facial keypoint, geometry estimation, facial features, expression classification, face region segmentation
기여
- MobileNetV1/V2에서 영감을 받았지만 구별되는 lightweight feature extraction network
- SSD(Single Shot MultiBox Detector)에서 수정된 GPU-friendly anchor scheme
- Non-maximum suppression 에 대한 개선된 tie resolution strategy 이 포함
Introduction
주요 기여는 다음과 같음:
- inference speed 관련하여,
- Mo bileNetV1/V2[3, 9]의 구조와 관련된 매우 컴팩트한 특징 추출기 컨볼루션 신경망으로, 경량 객체 감지를 위해 특별히 설계
- 효과적인 GPU 활용을 목표로 SSD[4]에서 수정된 새로운 GPU 친화적인 앵커 scheme
- 앵커[8] 또는 SSD 용어의 사전 정의는 네트워크 예측에 의한 조정의 기초 역할을 하고 예측 단위를 결정하는 사전 정의된 정적 경계 상자임
- prediction quality 관련하여,
- NMS [4, 6, 8]에 대한 대안으로, 중첩된 예측 간에 더 안정적이고 부드러운 연결 해결을 달성하는 연결 해결 전략임
Face detection for AR pipelines
제안된 프레임워크는 다양한 객체 감지 작업에 적용할 수 있지만, 본 논문에서는 휴대폰 카메라 viewfinder 에서 얼굴을 감지하는 데 중점
서로 다른 초점 거리와 일반적으로 캡처된 개체 크기로 인해 전면 및 후면 카메라에 대해 별도의 모델을 구축함
BlazeFace 모델
- 예측
- 축 정렬된 얼굴 직사각형을 예측
- 얼굴 회전(roll angle)을 추정할 수 있는 6개의 얼굴 키포인트 좌표(눈 중심, 귀 중심, 입 중심 및 코끝)를 생성
- 이러한 예측은 회전된 face rectangle 을 비디오 처리 파이프라인의 이후 task-specific 단계로 전달할 수 있게 하여 후속 처리 단계에서 상당한 변환 및 회전 불변성의 요구 사항을 완화 (섹션 5 : Applications) 참조)
Model architecture and design
BlazeFace model architecture 는 4가지의 중요한 설계 고려사항을 중심으로 구축함
Enlargning the receptive field sizes
대부분의 현대 CNN architecture(MobileNet 포함)는 모델 그래프를 따라 모든 곳에서 3x3 convolution kernel 을 선호하는 경향이 있지만 depthwise separable convolution 계산은 pointwise part 에 의해 지배됨
- size가 $ s \times s \times c $ 인 input tensor에서 $ k \times k $ depthwise convolution 은 $ s^{2} \times c \ times k^{2} $ 곱셈-덧셈 연산을 포함하는 반면, $d$ 출력 채널로의 후속 1 × 1 conv 는 dpethwise part 의 $ \frac{d}{k^{2}} $ 인수 내에서 연산 $ s^{2}cd $ 로 구성됨
실제로, 예를 들어 Metal Performance Shaders 구현[1]이 있는 Apple iPhone X에서 16비트 부동 소수점 산술의 3x3 깊이 방향 컨볼루션은 56x56x128 텐서의 경우 0.07ms가 걸리는 반면 128에서 128로의 후속 1×1 컨볼루션은 0.3ms에서 4.3배 느림
- 고정 비용 및 메모리 액세스 요인으로 인한 순수 산술 연산 수 차이만큼 중요하지 않음
이러한 관찰은 depthwise part 의 kernel size 를 늘리는 것이 상대적으로 저렴하다는 것을 의미
- 우리는 model architecture bottleneck 현상에 5x5 kernel을 사용하여 특정 receptive field size 에 도달하는 데 필요한 bottleneck 현상의 총량 감소를 커널 크기 증가와 교환 (그림 1)
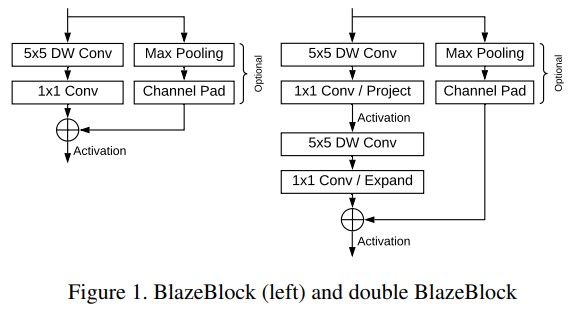
MobileNetV2 [9] bottleneck 에는 non-linearity 로 분리된 후속 depth-increasing expansion 과 depth-decreasing projection pointwise convolution 이 포함
Intermediate tensor 의 더 적은 수의 채널을 수용하기 위해, 병목 지점의 residual connection 이 “확장된”(증가된) channel resolution 에서 동작하도록 이러한 단계를 교환
마지막으로, depthwise convolution 의 낮은 overhead 로 인해 이 두 pointwise convolution 사이에 이러한 레이어를 추가할 수 있어 receptive field 크기 진행을 더욱 가속화할 수 있음
이것은 BlazeFace의 더 높은 추상화 수준 레이어에 대한 선택 병목으로 사용되는 double BlazeBlock 의 본질을 형성 (그림 1 오른쪽 참조)
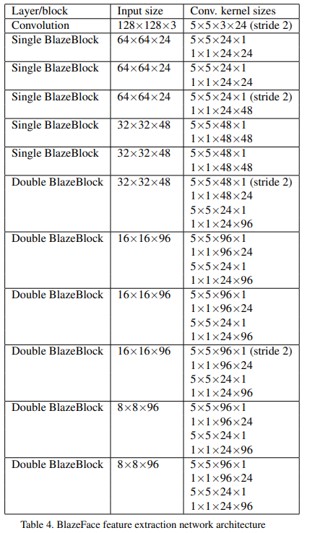
Featrue extractor
특정한 예로, 전면 카메라 모델의 feature extractor 에 초점을 맞춰보면..
- 더 작은 범위의 object scale 을 설명해야 하므로 계산 요구 사항이 더 낮음
- Extraction 구성
- input : 128 x 128 RGB
- 5개의 단일 BlazeBlock
- 6개의 이중 BlazeBlocks가 뒤따르는 2D convolution 으로 구성
- 가장 큰 tensor 의 depth(channel resolution)은 96
- 가장 작은 spatial resolution은 8x8
- 해상도를 1x1까지 낮추는 SSD와 대조됨
Anchor scheme
SSD와 같은 object detection model 은 사전 정의된 고정 크기 기본 경계 상자 또는 Faster-R-CNN[8] 에서 정의된 앵커에 의존함. Center offset 및 dimension 조절과 같은 일련의 regression(및 possibly classification) parameter 가 각 앵커에 대해 예측됨. 미리 정의된 앵커 위치를 좁은 경계 사각형으로 조정하는 데 사용.
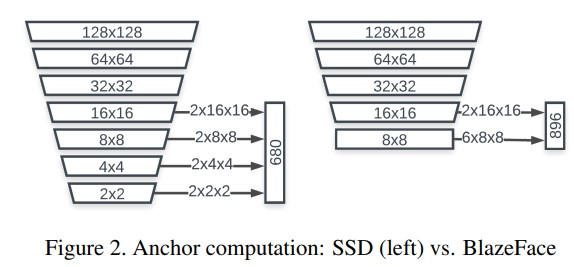
Object scale range 에 따라 여러 해상도 수준에서 앵커를 정의하는 것이 일반적임. 적극적인 downsampling 은 컴퓨팅 리소스 최적화를 위한 수단이기도 함. 일반적인 SSD 모델은 1x1, 2x2, 4x4, 8x8 및 16x16 feature 맵 크기의 예측을 사용. 그러나 PPN(Pooling Pyramid Network) 아키텍처[7]의 성공은 특정 기능 맵 해상도에 도달한 후 추가 계산이 중복될 수 있음을 의미.
CPU 계산과 달리 GPU 고유의 주요 기능은 특정 layer 계산을 디스패치하는 눈에 띄는 고정 비용이며, 이는 인기 있는 CPU 맞춤형 아키텍처에 고유한 심층 저해상도 계층에 상대적으로 중요함.
- 예를 들어, 한 실험에서 4.9ms의 MobileNetV1 추론 시간 중 실제 GPU shader 계산에 3.9ms만 소비됨을 관찰
이를 고려하여 추가 다운샘플링 없이 8x8 feature map dimension 에서 stop하는 대체 앵커 체계를 채택 (그림 2). 8×8, 4×4, 2×2 해상도 각각에서 픽셀당 2개의 앵커를 8×8에서 6개의 앵커로 교체. 사람의 얼굴 종횡비(aspect ratio) 의 제한된 변동으로 인해 앵커를 1:1 종횡비로 제한하는 것이 정확한 얼굴 감지에 충분하다는 것이 밝혀짐.
Post-processing
제안하는 feature extraction 은 8×8 이하의 해상도를 줄이지 않기 때문에 주어진 객체에 겹치는 앵커의 수는 객체 크기에 따라 크게 증가함. 일반적인 NMS 시나리오에서는 앵커 중 하나만 “승리”하고 최종 알고리즘 결과로 사용. 이러한 모델이 후속 video frame 에 적용될 때 예측은 서로 다른 앵커 사이에서 변동하는 경향이 있으며 temporal jitter (인간이 인지할 수 있는 노이즈)를 나타냄. 이 현상을 최소화하기 위해 suppression 알고리즘을 겹치는 예측 간의 weighted mean 으로 bounding box 의 regression parameter 를 추정하는 혼합(blending) 전략으로 대체함. 원래 NMS 알고리즘에 추가 비용이 거의 발생하지 않음.
- face detection task의 경우 이 조정으로 정확도가 10% 증가함
동일한 입력 이미지의 약간 offset 된 여러 버전을 네트워크에 전달하고 모델 결과(변환을 고려하여 조정됨)가 어떻게 영향을 받는지 관찰하여 jitter 의 양을 수량화함. 설명된 tie resolution strategy 수정 후 (원래 입력과 변위 입력에 대한 예측 간의 RMSE 로 정의된) jitter metric 은 전면 카메라 데이터 세트에서 40%, 더 작은 얼굴을 포함하는 후면 카메라 데이터 세트에서 30% 떨어짐.
Experiments
- 66K 이미지의 데이터 세트에서 모델을 학습
- 평가를 위해 2K 이미지로 구성된 지리적으로 다양한 개인 데이터 세트를 사용
- 전면 카메라 모델의 경우 의도된 사용 사례(후면 카메라 모델의 임계값은 5%)로 인해 이미지 영역의 20% 이상을 차지하는 얼굴만 고려함
- Regression parameter error 는 척도 불변성을 위해 안구간 거리(IOD)로 정규화하였고 절대 오차 중앙값은 IOD의 7.4%로 측정되었고, 위에서 언급한 절차에 의해 평가된 jitter metric 은 IOD의 3% 였음
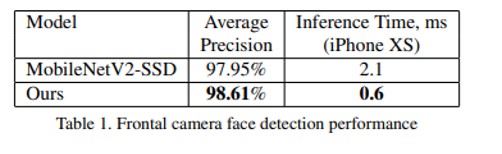
- 표 1은 제안된 정면 face detection 에 대한 average precision(AP)(표준 0.5의 교집합 경계 상자 일치 threshold 포함)과 모바일 GPU 추론 시간을 보여주고 이를 MobileNetV2(동일한 앵커 코딩 체계(MobileNetV2-SSD)를 사용하는 감지기) 기반 객체와 비교
- 추론 시간 평가를 위한 프레임워크로 16-bit floating point mode 에서 TensorFlow Lite GPU[2]를 사용했음
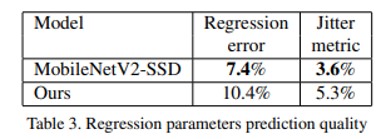
- 표 3은 모델 크기가 작아짐에 따라 regression parameter prediction quality 가 저하되는 정도를 보여줌
- 다음 섹션에서 살펴보겠지만, 이로 인해 전체 AR 파이프라인 품질이 반드시 비례적으로 저하되는 것은 아님
Applications
전체 이미지 또는 비디오 프레임에서 작동하는 제안된 모델은 거의 모든 얼굴 관련 컴퓨터 비전 응용 프로그램의 첫 번째 단계로 사용할 수 있다.
- 예 : 2D/3D 얼굴 키포인트, 윤곽 또는 표면 기하학 추정, 얼굴 특징 또는 표정 분류 및 얼굴 영역 분할
따라서 computer vision pipeline의 후속 작업은 적절한 얼굴 crop 측면에서 정의할 수 있다. BlazeFace에서 제공하는 몇 가지 얼굴 키포인트 추정값과 결합하여 이 crop을 회전하여 내부의 얼굴이 중앙에 있고 크기가 정규화되고 roll angle가 0에 가까우도록 할 수도 있다. 이것은 task-specific model에서 상당한 translation 및 rotation 불변성에 대한 요구 사항을 제거하여 더 나은 계산 resource allocation을 허용.
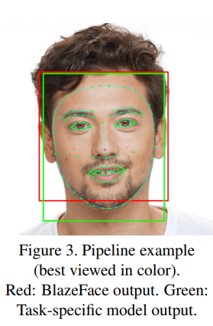
얼굴 윤곽 추정(face contour estimation)의 예를 통해 이 파이프라인 방식을 설명한다. 그림 3에서 우리는 Blaze Face의 출력, 즉 예측된 경계 상자와 얼굴의 6개 키포인트(빨간색)가 약간 확장된 crop에 적용된 보다 복잡한 얼굴 윤곽 추정 모델에 의해 어떻게 더 정제되는지 보여준다. 자세한 키포인트는 face detector를 실행하지 않고 후속 프레임에서 추적에 재사용할 수 있는 더 미세한 경계 상자 추정값(녹색)을 생성한다. 이 computation saving 전략의 실패를 detect하기 위해 윤곽 모델은 얼굴이 실제로 존재하고 제공된 직사각형 자르기에 합리적으로 정렬되었는지 여부도 감지할 수 있다. 해당 조건을 위반할 때마다 BlazeFace face detector가 전체 비디오 프레임에서 다시 실행된다.
이 논문에서 설명하는 기술은 mobile에서 major AR self-expression application 과 AR developer APIs를 drive 하고 있음.
Leave a comment