Learning Spatiotemporal Features with 3D Convolutional Networks (C3D) 리뷰
Updated:
Learning Spatiotemporal Features with 3D Convolutional Networks (C3D) 리뷰
논문 다운 링크
https://arxiv.org/pdf/1412.0767.pdf
2015년에 발표된 논문인 것을 감안하여 읽으시기를 추천드립니다. 저 같은 경우 아이디어에 대해 궁금해서 읽어서 중간에 생략된 부분이 있을 수 있습니다.
Abstract
large supervised video dataset을 학습하는 deep 3-dimensional convolutional networks (3D ConvNets) 제안한다. 3가지 발견을 했다.
- 2D ConvNets보다 spatiotemporal feature를 학습하는데 더 적합하다.
- 3D ConvNets에서 3x3x3 kernel size가 가장 좋은 성능을 가진다.
- 제안하는 C3D는 4개의 dataset에서 sota를 2개 dataset에서 좋은 성능을 보여준다.
Introduction
대규모 비디오 작업을 균질한 방식으로 해결하는 데 도움이 되는 일반 비디오 디스크립터에 대한 요구가 여전히 증가하고 있다. 효과에는 4가지 속성이 있다.
- 차별적이면서도 다양한 유형의 비디오를 잘 표현할 수 있도록 일반적이어야 한다. (인터넷 비디오는 풍경, 자연 장면, 스포츠, TV 쇼, 영화, 애완 동물, 음식 등)
- 디스크립터는 컴팩트해야 한다.
- 시스템은 효율적으로 계산해야 한다. 그러므로 디스크립터는 간단한 모델에서도 잘 동작해야 한다.
본 논문에서는 Deep 3D ConvNet을 사용하여 spatiotemporal 특징을 학습할 것을 제안한다.
contribution은 아래와 같다. - 3D Convolution deep network가 appearance와 motion을 동시에 modeling하는 좋은 feature learning machine임을 보여줌
- 실험적으로 3x3x3 conv kernel이 가장 잘 잘 동작하는 것을 발견함
- 4가지 work와 6가지 benchmark에서 좋은 성능을 냄
- compact하고 효율적으로 계산할 수 있음
Related Work
(중략) 3D ConvNet은 이전에도 있었지만 우리의 방식은 전체 비디오 프레임을 입력으로 사용하고, 전처리에 의존하지 않으므로 큰 데이터 세트로 쉽게 확장 가능하다.
Learning Features with 3D ConvNets
3D convolution and pooling
3D Convolution 및 3D Pooling으로 인해서 시간 정보를 더 잘 모델링할 수 있으므로 3D ConvNet이 2D ConvNet보다 좋다고 생각한다. 그림 1은 그 차이점을 보여준다. 실험으로는 대규모는 오래걸리니 중간 규모의 UCF-101 dataset을 이용해 실험한다. kernel의 경우 2D ConvNet에서 3x3 conv kernel이 좋은 성능을 보였으므로 공간 receptive field는 3x3 으로 고정을 하고 temporal depth만 변경한다. 실험 설정은 아래와 같다.
모든 비디오를 128 x 171로 resize한다. 비디오는 non-overlapping하게 16 프레임 클립으로 분할된 후 입력으로 사용한다. 그리고 학습 중에 h,w에 대해 112로 random crop을 사용하여 학습한다.
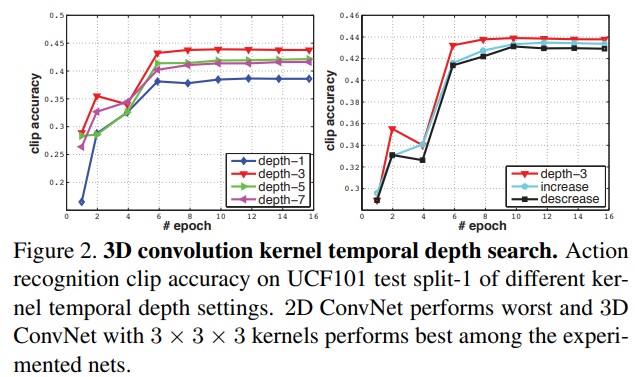
Exploring kernel temporal depth
각 depth만 변경해가며 실험을 하였다. 비교는 그림 2에 있다. 차이가 적긴 하지만 depth가 3일 때 가장 좋은 성능을 보였다. 따라서 3x3x3이 3D ConvNet에서 최상의 conv filter이다.
Spatiotemporal feature learning
네트워크 아키텍처는 그림 3과 같으며 3x3x3 kernel을 사용하였다. 초기 단계에서 시간 정보를 보존하기 위해 pool 1에서만 1x2x2 kernel을 사용하였다. 현재 가장 큰 video classification benchmark인 Sports-1M dataset에서 학습을 하였다. 110만개의 스포츠 비디오로 구성되어있으며 487 class로 되어있다. UCF-101에 비해서 category는 5배, 동영상 수는 100배 많다. 동영상은 2초 길이의 클립 5개를 무작위로 추출하며 128x171로 프레임 size를 resize한 후 112x112 로 random crop을 진행한다. 50%확률로 filp도 함. minibatch는 30개를 사용하였고 SGD optimizer를 사용하였다. learning rate는 0.003이고 150K iteration마다 2로 나눈다. 최적화는 1.9M iter (19epoch)이다. 학습 한 C3D는 다른 video 분석 task에 feature extractor로 사용될 수 있다.

Action Recognition
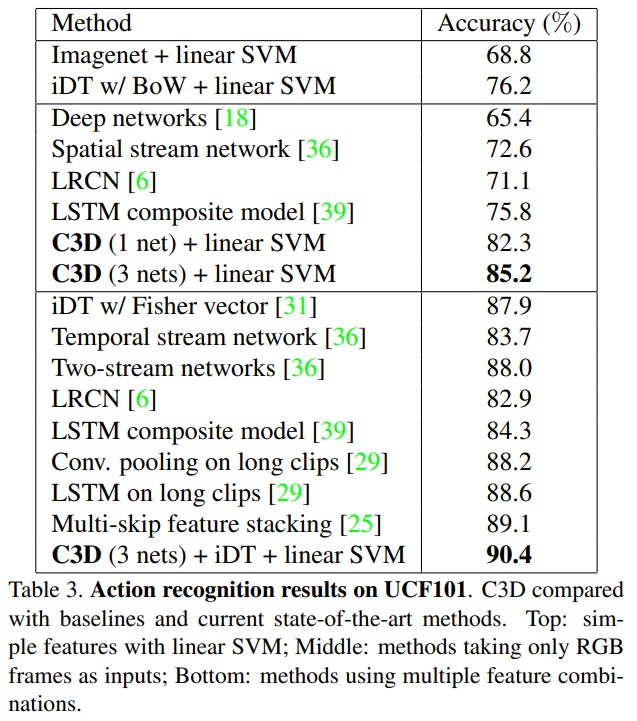
UCF-101 dataset으로 평가한다. 101 class의 13,320개의 비디오로 구성되어 있다. 결과는 표 3에 있다. C3D의 경우 모두 fine-tuning한 model이다. 가운데는 입력을 RGB로만 사용한 것이며, 3개의 network의 경우 차원이 4,096에서 12,288로 증가하여 정확도가 85.2%로 향상된 것을 확인할 수 있다.
Action Similarity Labeling, Scene and Object Recognition, Runtime Analysis
읽고자 하였던 부분이 아니라 생략하였습니다.
Conclusions
3D ConvNet을 사용하여 시공간 feature 학습 문제 해결 시도하였다. 3x3x3 kernel이 좋은 결과를 가져오는 것을 확인하였고 여러 benchmark에서 좋은 성능을 가져왔다.
Appendix
각 layer에서의 feature를 visualization한 결과를 보여주었다. layer가 higher해질수록 변화하는 과정에 초점을 두면 흥미로운 결과이다.







Leave a comment