Knowledge Distillation이란?
Updated:
Knowledge Distillation or Distillation learning
참고 블로그 : https://light-tree.tistory.com/196
“Distilling the Knowledge in a Neural Network” (NIPS 2014)
목적
미리 잘 학습된 큰 네트워크(Teacher Network)의 Knowledge를 실제로 사용하고자 하는 작은 네트워크(Student Network)에게 전달하는 것이 목적이다. 여기서 Teacher Network는 일반적으로 더 깊은 네트워크이기 때문에 파라미터 수가 많고, 연산량이 많아 feature extraction이 더 잘 되는 네트워크이다. 그렇다면 왜 큰 네트워크를 사용하면 되지 굳이 작은 네트워크로 전달을 할까?
바로 작은 모델로 더 큰 네트워크의 성능을 얻을 수 있다면 CPU or GPU, 배터리, 메모리 측면에서 더 효율적이기 때문이다. 따라서, 학습 과정에서 큰 네트워크의 Knowledge를 작은 네트워크에 전달하여 작은 네트워크의 성능을 높이겠다는 목적을 가지고 있다.
아키텍처
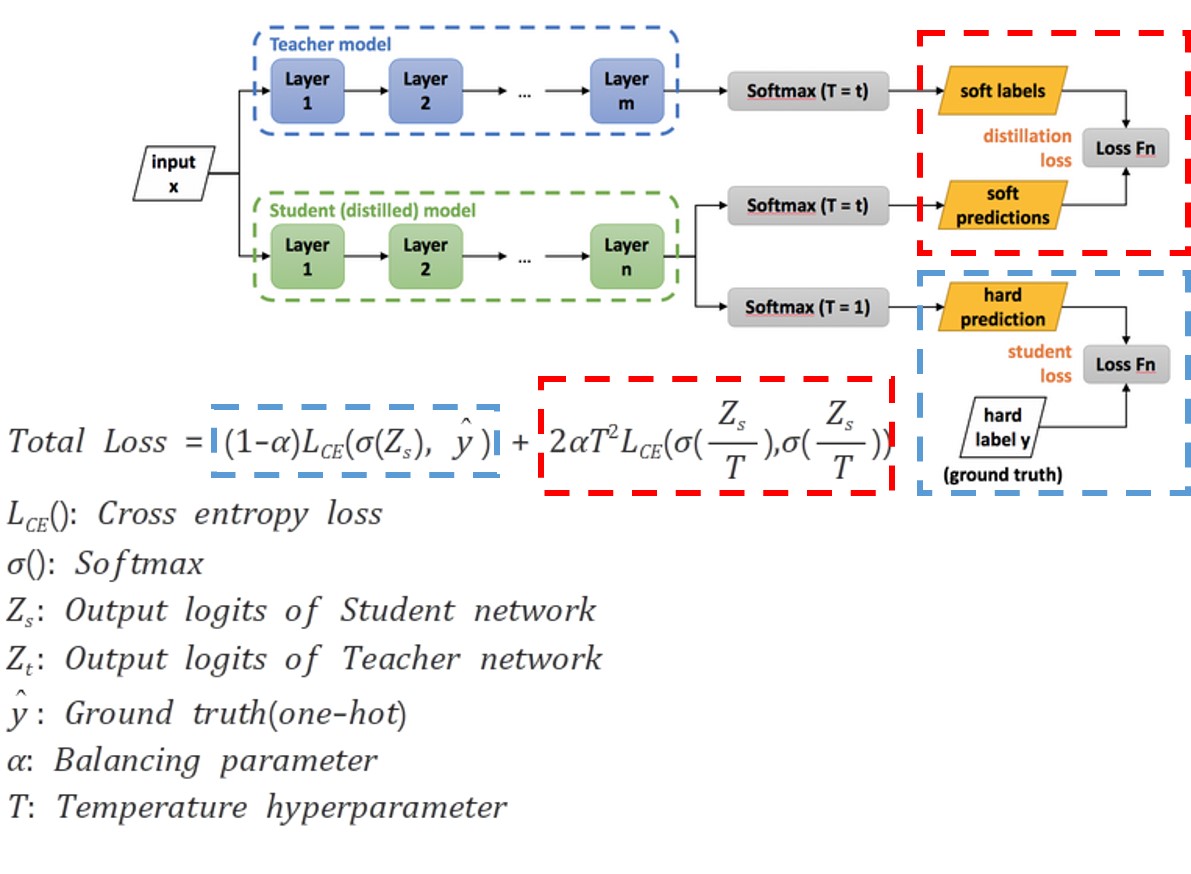
이미지 출처: https://nervanasystems.github.io/distiller/knowledge_distillation.html
Loss는 총 2개의 텀으로 구성되어 있다. 첫 번째 텀(빨간색)은 Teacher Network와 Student Network 사이의 Cross Entropy Loss이다. 두 번째 텀(파란색)은 Student Network의 classification 성능에 대한 Cross Entropy Loss이다.
Soft prediction은 softmax 그대로 사용하는 것이고 (총합이 1이 되도록), Hard prediction은 softmax 이후 one-hot vector로 제일 큰 값만 1을 가지고 나머지는 0을 가지도록하는 것을 말한다. Teacher Network를 더 잘 모방하도록 빨간색 Loss의 경우 Soft label을 사용한다.
Hyperparameter는 총 2개이다. Balancing parameter는 2개의 Loss의 가중치를 의미하며 Temperature byperparameter는 softmax 함수의 결과로 나온 값의 불균형을 조금 완화해주는? 역할이다. 따라서 그림에서 T=t 값을 조절하여 soft label을 ㅅ하용하는 이점을 최대화한다.
Leave a comment