Omni-sourced Webly-supervised Learning for Video Recognition 리뷰
Updated:
Omni-sourced Webly-supervised Learning for Video Recognition 리뷰
논문 다운 링크
https://arxiv.org/pdf/2003.13042.pdf
Abstract
OmniSource
- Web data를 활용하여 video recognition 모델을 학습시키는 새로운 프레임워크
- Webly-suprevised learning을 위해 data format(예: images, short videos, long untrimmed videos)간의 장벽을 극복
- 첫째, (1. task-specific collection으로 선별 + 2. teacher model에 의해 automatically filter)된 multiple format의 데이터 샘플이 통합된 형식으로 변환된다. 그런 다음 Webly-suprevised learning에서 도메인 gaps(여러 data source와 format간)를 처리하기 위한 joint-training strategy이 제안
- data balancing, resampling, cross-dataset mixup과 같은 좋은 것들이 joint training에 사용
- 실험에서, OmniSource는 multiple source와 format의 데이터를 활용하여 training에서 데이터 효율성이 더 높은 것을 확인
- 사람의 labeling 없이 인터넷에서 크롤링한 350만 이미지와 800,000분 분량의 동영상으로(이전 작업의 2% 미만) OmniSource로 학습한 모델은 2D 및 3D-ConvNet baseline 모델의 (Kinetics-400 benchmark에서) Top-1 정확도를 3.0% 및 3.9%를 향상
- OmniSource를 사용하여 비디오 인식을 위한 다양한 pre-training stategy로 새로운 record을 수립
- 최고의 모델은 scratch training, ImageNet pre-training 및 IG-65M pre-training에 대해 Kinetics-400 benchmark에서 각각 80.4%, 80.5%, 83.6%의 Top-1 정확도를 달성
Introduction
Image recognition에서 representation learning은 큰 성공을 이루었고, 더 큰 규모의 데이터셋이 최근에 많이 나오면서 video classificaion이 크게 발전을 하였다. 하지만 이러한 큰 데이터셋에 labeling하는 건 많은 시간과 비용이 소요된다. trimmed video recognition은 더더욱 어렵다 ( 대부분의 온라인 video가 untrimmed이므로). 그래서 video를 보고 특정 query를 기반으로 수동으로 잘라 클립을 만들어야하는데 굉장히 많은 노력이 필요로 한다. 그 결과 지난 3년동안 Web video는 기하급수적으로 늘어났지만, Kinetics 데이터셋의 경우에는 400개 class의 300K video, 700 class의 650K video이므로 video architecture의 확장을 제한한다고 볼 수 있다.
label이 잘 된 trimmed video에 스스로 국한시키는 대신, 더 노동 절약적인 방식으로 인터넷에서 공개적으로 사용할 수 있는 풍부한 시각적 데이터를 탐색함으로써 넘어가보자. 이러한 시각적 데이터는 이미지, 짧은 동영상, 긴 동영상 등 다양한 형식으로 되어 있고, 서로 다른 장점을 나타내면서 동일한 시각적 세계를 포착한다.
- 이미지의 quality가 향상되고 distinctive moment에 초점이 맞춰질 수 있음
- 짧은 비디오는 사용자가 편집할 수 있으므로 더 많은 정보를 포함
- 긴 비디오는 multiple view에서 event를 묘사 가능
논문에서는 single model이 서로의 장점을 결합할 수 있도록 다양한 형식의 데이터를 통합된 형식으로 변환
최근 작업은 레이블이 지정되지 않은 방대한 웹 이미지 또는 해시태그만 있는 비디오에서 pre-training의 가능성을 탐구한다. 그러나 아래의 단점을 가지고 있다.
- 단일 형식의 데이터로 범위를 제한한 경우이며
- 이러한 방법은 일반적으로 노이즈에 탄력적인 pre-training된 2D CNN 모델을 얻기 위해 수십억 개의 이미지가 필요하므로 비용이 많이 들고 실용성이 제한됨
- 게다가, 비디오용 대규모 이미지에서 학습된 representation을 활용하려면 inflating or distillation을 통해 2D ConvNet을 3D counterpart로 전송하는 extra step을 수행한 다음 target dataset에서 fine-tuning을 수행해야 한다 ->지루하고 차선책일 수 있음
본 논문은
- 서로 다른 형식의 웹 데이터의 여러 소스를 동시에 활용하면서 비디오 분류를 위한 간단하고 통합된 프레임워크를 제안
- 데이터 효율성을 향상시키기 위해 우리는 작업별 데이터 수집, 즉 검색 엔진에서 클래스 레이블을 키워드로 사용하여 최상위 결과를 얻어 감독을 가장 유익한 정보로 만드는 것을 제안
프레임워크는 세 단계로 구성
- (1) 레이블이 지정된 dataset에서 하나(또는 그 이상)의 teacher network를 학습
- (2) 수집된 각 data source에 대해 해당 teacher network를 적용하여 pseudo-label을 얻고 관련 없는 샘플을 낮은 신뢰도로 filtering
- (3) 각 유형의 Web data(예: 이미지)를 대상 input format(예: 비디오 클립)으로 변환하고 student network를 학습하기 위해 서로 다른 변환을 적용
labeled dataset과 unlabeled web dataset를 사용한 joint training에는 아래의 두 가지 주요 장애물이 존재
- 첫째, possible domain gap이 발생
- 예를 들어, 웹 이미지는 비디오보다 물체에 더 초점을 맞추고 모션 블러를 덜 포함할 수 있음
- 둘째, teacher filtering은 여러 클래스에 걸쳐 불균형한 데이터 분포로 이어질 수 있음
첫 번째 문제인 domain gap을 줄이기 위해서는 labeled dataset과 unlabeled web dataset 간의 training batch size balance를 맞추고 cross-dataset mixup을 적용할 것을 제안. 두 번째 문제인 데이터 불균형에 대처하기 위해 우리는 몇 가지 resampling 전략을 시도. 이러한 모든 기술은 우리 접근 방식의 성공에 기여하였다.
우리의 방법은 이전 방법과 비교하여 다음과 같은 측면에서 탁월하다.
- (1) Omnisource fashion을 목표로 Images, Trimmed video, Untrimmed video를 포함하는 웹 데이터 형식을 하나의 학생 네트워크로 혼합하여 활용
- (2) data-efficient
- 경험적 결과에 따르면 Kinetics의 총 프레임 수(240K 비디오, ~70M 프레임)에 비해 훨씬 적은 양인 2M 이미지만 있으면 눈에 띄는 개선(약 1%)이 생성된다. trimmed video의 경우 필요한 양은 약 0.5M다. 대조적으로 [13,50]에서 noise-resilient가 있는 pre-trained model을 얻기 위해 65M 비디오가 수집된다.
우리의 프레임워크가 수십억 개의 이미지 또는 비디오에서 대규모로 weakly-supervised pre-training의 이점을 얻을 수 있다는 점도 주목할 만하다.
- 경험적 결과에 따르면 Kinetics의 총 프레임 수(240K 비디오, ~70M 프레임)에 비해 훨씬 적은 양인 2M 이미지만 있으면 눈에 띄는 개선(약 1%)이 생성된다. trimmed video의 경우 필요한 양은 약 0.5M다. 대조적으로 [13,50]에서 noise-resilient가 있는 pre-trained model을 얻기 위해 65M 비디오가 수집된다.
요약하자면 우리의 기여는 다음과 같다.
(1) 다양한 format의 웹 데이터를 활용할 수 있는 간단하고 효율적인 webly-supervised video classification 프레임워크인 OmniSource를 제안
(2) source-target balancing, resampling, cross-dataset mixup을 포함하여 Omni-source data를 사용한 joint training 중 문제에 대한 모범 사례를 제안
(3) 실험에서 OmniSource에 의해 학습된 저자의 모델이 우리가 테스트한 모든 pre-training strategy에 대해 Kinetics-400에서 state-of-the-art를 달성
Related work
[Webly-supervised learning]
웹 지도 학습(webly-supervised learning)이라고 하는 인터넷 정보를 활용하는 방법이 광범위하게 연구
- Divvala 등[8]은 visual concept 발견 및 image annotation을 위해 online resource에서 모델을 자동으로 학습할 것을 제안
- Chen et al[6]은 인터넷에서 크롤링한 이미지가 fully-supervised method보다 우수한 결과를 얻을 수 있음을 밝혔다
- Ma et al은 [29]에서 비디오 분류를 위해 web action images를 수동으로 필터링하는 대신 web images를 사용하여 action recognition model을 향상시킬 것을 제안
- 추가적인 human labor를 없애기 위해 video concep detector를 학습하거나 비디오에서 관련 프레임을 선택하려는 노력이 있었음
이러한 방법은 프레임을 기반이므로 비디오의 풍부한 temporal dynamic을 고려하지 못한다. Recent work에서는 webly-supervised learning이 매우 큰 규모의 noisy data(~ $10^{9}$ 개 이미지 및 ~ $10^{7}$ 개 비디오)로 더 나은 pre-training model을 생성할 수 있음을 보여준다. pre-training step과 orthogonal하기 때문에 제안하는 프레임워크는 joint-training paradigm에서 동작하며 large-scale pre-training을 보완한다.
[Semi-supervised learning]
우리의 프레임워크는 labeled와 unlabeled web data가 공존하는 semi-supervised setting에서 동작
대표적인 고전적 접근 방식
- label propagation[63], self-training[37], co-training[1], graph network[22]
Deep model에서는
- generative models[21], self-supervised learning[55], concensus of multiple experts[56]
를 통해 unlabeled data에서 직접 학습할 수 있다. 그러나 대부분의 기존 방법은 소규모 데이터 세트에서만 검증되었다. 한 concurrent work[50]은 먼저 pseudo-labels이 있는 unlabeled 데이터로 student 네트워크를 훈련한 다음 labeled 데이터 세트에서 fine-tuning하는 것을 제안한다. 그러나 우리의 프레임워크는 pretrain-finetune 패러다임에서 벗어나 두 source에서 동시에 동작하며 데이터 효율성이 더 높다.
[Distillation]
- knoweledge distillation 및 data distillation 설정에 따라 manually labeled data가 주어지면 supervised learning으로 base model을 학습할 수 있고, 그런 다음 모델은 unlabeled data 또는 해당 transform에 적용
- 이전의 대부분의 노력은 이미지 영역에 국한
- 우리의 프레임워크는 단일 네트워크 내에서 여러 source와 format의 knoweledge를 추출
[Domain Adaptation]
- multiple source의 web data를 input으로 사용하기 때문에 필연적으로 domain gap이 존재
- Domain adaptation에 대한 이전의 시도[7,46,4]은 데이터 분포 측면에서 data shift[35]을 완화하는 데 중점
- 반대로 우리의 프레임워크는 different format(예: still images, long videos)의 시각적 정보를 same format(예: trimmed video clip)으로 조정하는 데 중점
[Video classification]
- 비디오 분석은 오랫동안 hand-crafted feature를 사용하여 해결
- 딥 러닝의 성공에 따라 video classification architecture는 두 가지 families of models(예: two-stream 및 3D ConvNets)에 의해 지배
- two-stream : 2D 네트워크를 사용하여 image-level의 feature를 추출하고 top에서 temporal aggregation을 수행
- 3D ConvNets : video cflip에서 직접 공간-시간적 feature를 학습
Method
[3.1 Overview]
- 프레임워크는 다양한 소스(search engine, social media, video sharing platform)의 다양한 형태(images, trimmed videos, untrimmed videos)의 web data를 통합된 방식으로 활용
[3.2 Framework formulation]
Target task(예: trimmed video recognition)과 해당 대상 데이터 세트 $D_{T}$ = ${(x_{i} , y_{i} )}$ 가 주어지면 unlabeled web resource $U$ = $U_{1} ∪ · · · ∪ U_{n}$ 를 활용하는 것을 목표로 한다(여기서 $U_{i} $ ) 는 특정 source 또는 format의 unlabeled를 나타냄).
- 첫째, $U_{i}$ 에서 pseudo-labeled dataset $\hat{D}_{i}$ 를 구성
- confidence가 낮은 sample은 $D_{T}$ 에 대해 학습된 teacher model $M$ 을 사용하여 제거하고 나머지 데이터는 pseudo-labeled $\hat{y}$ = $PseudoLabel(M(x))$ 로 할당
- 둘째, specific format(예: still images, long videos)의 데이터를 대상 작업의 data format(우리의 경우 trimmed video)으로 처리하기 위해 적절한 변환 $T_{i}(x)$ : $\hat{D}{i}$ → $D{A,i}$ 를 고안한다. auxiliary dataset $D_{A}$ 가 되도록 $D_{A,i}$ 의 합집합을 나타낸다.
- 마지막으로, 모델 $M_{0}$ (무조건 원래 M은 아님)은 $D_{T}$와 $D_{A}$ 에 대해 jointly train될 수 있다.
각 반복에서 우리는 각각 $D_{T}$ , $D_{A}$ 에서 데이터 $B_{T}$ , $B_{A}$ 의 두 개의 mini-batch를 샘플링한다. Loss는 Eq 1로 표시된 $B_{T}$ 와 $B_{A}$ 의 cross entropy loss의 합이다.
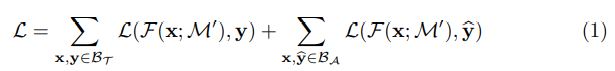
명확히 하기 위해 표 1의 10억 규모의 webly-supervised learning에 대한 최근 작업과 프레임워크를 비교한다. OmniSource는 multiple source의 web data를 처리할 수 있다. specific task를 돕도록 설계되었으며 webly-supervision을 pre-training 대신 multiple data source에 대한 co-training으로 취급하므로 훨씬 더 데이터 효율성이 높다. 또한 우리의 프레임워크가 webly-supervised pre-training[13]과 orthogonal한다는 점도 주목할 만하다.

[3.3 Task-specific data collection]
추가적인 query expansion 없이 클래스 이름을 데이터 크롤링의 키워드로 사용한다. Instagram과 같은 태그 기반 시스템의 경우 automatic permutation 및 stemming(예: beekeeping을 beekeep이나 keeping bee라고 바꿀 수 있다)을 사용하여 태그를 생성한다. 우리는 search engine, social media, video sharing platform을 포함한 다양한 source에서 web data를 크롤링한다. Google은 각 query에 대한 결과 수를 제한하기 때문에 여러 query를 수행하며 각 query는 특정 기간에 의해 제한된니다. 해시태그와 함께 대규모 web data에 의존하는 이전 작업에 비해 우리의 task-specific collection은 label과 높은 상관 관계가 있는 키워드를 사용하여 supervision을 강화한다. 또한 필요한 web data의 양을 100배(예: Instagram의 65M에서 0.5M 비디오)로 줄인다.
데이터 수집 후에는 먼저 유효하지 않거나 손상된 데이터를 제거한다. Web data에는 validation data와 매우 유사한 샘플이 포함될 수 있으므로 공정한 비교를 위해 데이터 “중복 제거”가 필수적이다. Feature 유사성을 기반으로 content-based data 중복 제거를 수행한다. 먼저 ImageNet pre-trained ResNet50을 사용하여 frame-level feature를 추출한다. 그런 다음 web data와 target dataset 간의 cosine similarity를 계산하고 whitening 후 pairwise comparison를 수행한다. 동일한 프레임의 서로 다른 crop 간의 mean similarity가 임계값으로 사용된다. 위의 유사성은 의심스러운 중복을 나타낸다. Kinetics-400의 경우 4,000개의 web images(3.5M 중 0.1%)와 400개의 web videos(0.5M 중, 0.1%)를 필터링한다. 우리는 그들 중 일부를 수동으로 검사하고 10% 미만이 실제 중복임을 발견했다.
[3.4 Teacher filtering]
Web에서 크롤링하는 데이터는 필연적으로 noisy하다. 수집된 web data를 joint training에 직접 사용하면 상당한 성능 저하(3% 이상)가 발생한다. 관련 없는 데이터가 training set를 오염시키는 것을 방지하기 위해 먼저 대상 데이터 세트에서 teacher network M을 훈련하고 confidence가 낮은 web data를 폐기한다. Web images의 경우 3D teacher를 2D로 축소할 때 성능 저하가 관찰되므로 2D teacher만 사용한다. Web videos의 경우 적용 가능한 teacher와 3D teacher 모두 2D teacher보다 지속적으로 우수한 성과를 보인다.
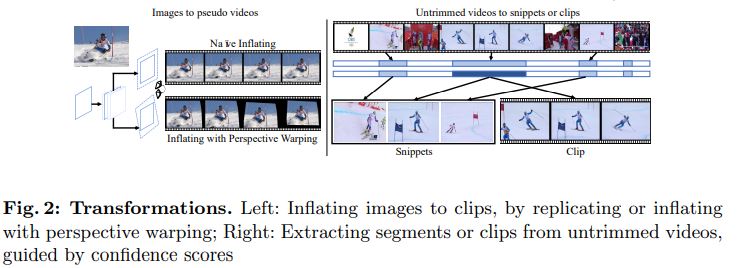
[3.5 Transforming to the target domain]
#####Web Images.
Video recognition training을 위한 web images를 준비하기 위해 이미지를 pseudo(유사) 비디오로 변환하는 몇 가지 방법을 고안한다.
- 첫 번째 순진한 방법은 이미지를 n번 복사하여 n-frame clip을 형성하는 것이다. 그러나 이러한 clip은 시간이 지남에 따라 시각적으로 변하는 static clip과 natural videos 사이에 가시적인 gap이 있기 때문에 최적이 아닐 수 있다.
- 따라서 우리는 moving camera로 보는 static images로부터 vidoe clip을 생성하는 것을 제안한다. 이미지 I가 주어졌을 때 standard perspective projection model[10]에서 다른 perspective(원근) $\tilde{I}$ 를 가진 이미지는 homographic transform $H ∈ R$ 3×3, 즉 $\tilde{I} = H(I) = F(I; H)$ 이다. $J_{1} = I$ 에서 시작하여 I에서 클립 $J$ = ${J_{1}, · · · , J_{N} }$ 을 생성하려면 식 (2)가 있다.
각 행렬 $H_{i}$ 는 multivariate Gaussian distrimbution N(μ, Σ)에서 무작위로 샘플링되는 반면 parameter μ와 Σ는 원본 video source에 대한 maximum likelihood estimation을 사용하여 추정된다. pseudo videos를 얻으면, trimmed video dataset을 사용하여 joint training을 위해 web images를 활용할 수 있다.
Untrimmed Videos.
Untrimmed videos는 web data의 중요한 부분을 형성한다. video recognition에서 untrimmed video를 활용하기 위해 2D 및 3D 아키텍처에 대해 각각 다른 변환을 채택한다. 2D TSN의 경우, 전체 비디오에서 드물게 샘플링된 snippet이 입력으로 사용된다. 먼저 낮은 프레임 속도(1FPS)로 전체 비디오에서 프레임을 추출한다. 2D teacher는 각 프레임의 confidence score를 얻는 데 사용되며 프레임도 positive와 negative frame으로 나눈다. 실제로 우리는 snippet을 구성하기 위해 positive frame만 사용하는 것이 차선책이라는 것을 알게 되었다. 대신에 negative frame과 positive frame을 결합하면 더 harder example이 만들어지고 결과적으로 더 나은 recognition performance를 얻을 수 있다. 우리의 실험에서는 1개의 positive frame과 2개의 negative frame을 사용하여 3-snippet input을 구성한다. 3D ConvNet의 경우 video clip(조밀하게 샘플링된 연속 프레임)이 입력으로 사용됩니다. 먼저 untirmmed video를 10초 clip으로 자른 다음 3D teacher를 사용하여 confidence score를 얻는다. Joint training에는 positive clip만 사용된다.
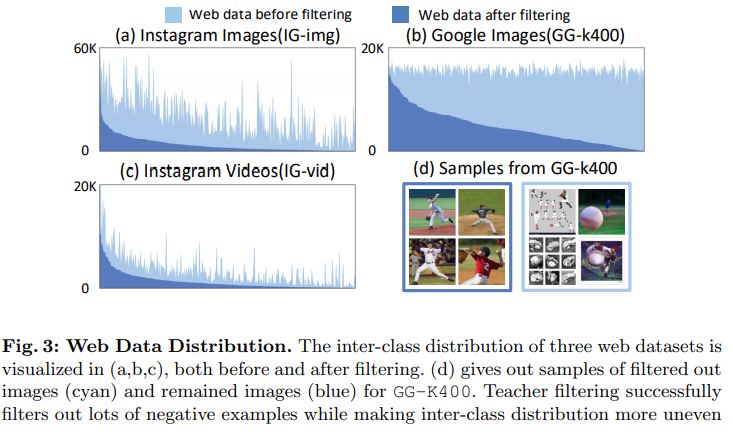
[3.6 Joint training]
Web data가 필터링되고 target datast $D_{T}$ 와 동일한 형식으로 변환되면 auxiliary(보조) dataset $D_{A}$ 를 구성한다. 그런 다음 Eq 1의 Cross Entropy Loss 합을 사용하여 $D_{T}$ 와 $D_{A}$ 로 네트워크를 학습할 수 있다. 그림 3에서 볼 수 있듯이 클래스 전체의 Web data는 특히 teacher filtering 후에 매우 불균형하다. 또한 $D_{T}$ 와 $D_{A}$ 사이에 잠재적인 domain gap이 존재한다. 이러한 문제를 완화하기 위해 다음과 같이 몇 가지 좋은 사례를 열거한다.
Balance between target and auxiliary mini-batches.
auxiliary dataset은 target dataset보다 훨씬 크고 domain gap이 발생할 수 있으므로 target mini-batch와 auxiliary mini-batch 간의 데이터 비율은 최종 성능에 매우 중요하다. 실험적으로 | $B_{T}$ | : | $B_{A}$ | = 2 : 1 ∼ 1 : 1이 적당하게 잘 작동한다.
Resampling strategy.
Web data는 특히 teacher filtering 이후에 매우 불균형하다(그림 3 참조). 이를 완화하기 위해 몇 가지 sampling을 탐색한다.
- (1) clipped distribution에서 sampling : sample이 임계값 $N_{c}$ 를 초과하는 클래스는 자른다.
- (2) 거듭제곱(power law) 법칙에 의해 수정된 분포에서 sampling : N개의 sample로 클래스를 선택할 확률은 $N^{p}$ (p ∈ (0, 1))에 비례한다.
p = 0.2로 parameterize되는 (2)가 일반적으로 더 나은 방법이라는 것을 실험적으로 얻었다.
Cross-dataset mixup.
Mixup[57]은 이미지 인식에서 널리 사용되는 전략이다. 학습을 위해 example pair와 label의 convex combination을 사용하여 deep neural netwrok의 generalization을 개선한다. 우리는 그 기술이 video recognition에도 동작한다는 것을 발견했다. $D_{T}$ 에서만 teacher 네트워크를 학습할 때, 두 개의 clip-label pair의 linear combination을 training data로 사용하며 이를 intra-dataset mixup이라고 한다. target dataset와 auxiliary dataset가 모두 사용되는 경우 두 pair은 두 dataset에서 무작위로 선택된 샘플이며 이를 cross-dataset mixup이라고 한다. Mixup은 네트워크가 처음부터 학습될 때 상당히 잘 동작한다. Fine-tuning의 경우, 성능 향상이 눈에 띄지 않는다.
Datasets
이 섹션에서는 실험을 수행할 dataset을 소개한다. 그런 다음 web data가 수집되는 다양한 source를 살펴본다.
[4.1 Target datasets]
Kinetics-400.
- 가장 큰 video dataset 중 하나며, 2017년에 출시된 버전을 사용
- 400개의 classes, 각 category는 400개 이상의 비디오
- 전체적으로 training, validation, test subset에 대해 각각 약 240K, 19K 및 38K 비디오
- 각 비디오에는 10초 길이의 clip에 주석이 추가되고 레이블이 지정
- 이 10초 클립은 기본 지도 학습 설정에 대한 데이터 소스를 구성하며 이를 K400-tr이라고 함
- training video의 나머지 부분은 K400-untr이라고 하는 인터넷에서 제공되는 untrimmed video를 모방하는 데 사용
Youtube-car.
- 196가지 유형의 자동차에 대한 10K training 및 5K test video가 포함된 fine-grained video dataset
- 비디오는 untrimmed이며 몇 분 동안 지속
- 논문에 따르면 4 FPS의 비디오에서 프레임을 추출
UCF101.
- 101개의 class와 각 class에 약 100개의 video가 있는 소규모 video recognition dataset
- 실험에서는 official split-1을 사용
- training 및 test용으로 약 10K 및 3.6K 비디오 존재
[4.2 Web sources]
우리는 search engines, social media 및 video sharing platform을 포함한 다양한 source에서 web images와 videos를 수집하였다.
GoogleImage
- Kinetics400, Youtube-car 및 UCF101용 search engine 기반 web data source
- 관련 web image를 얻기 위해 Google에서 target datset의 각 class 이름을 query
- Kinetics400, Youtube-car 및 UCF101에 대해 각각 6M, 70K, 200K URL을 크롤링
- 데이터 정리 및 teacher filtering 후 이 세 가지 dataset에 대해 약 2M, 50K, 100K 이미지가 학습에 사용
- 3개의 datsaet를 각각 GG-k400, GG-car 및 GG-UCF로 표시
- Kinetics-400용 social media 기반 web data source
- InstagramImage와 InstagramVideo로 구성
- Kinetics-400에서 각 class에 대해 여러 tag를 생성하여 1,479개의 태그와 870만 개의 URL을 생성
- 손상된 data 및 teacher filtering을 제거한 후 약 150만 이미지와 500K 비디오가 IG-img 및 IG-vid로 표시된 joint-training에 사용
- 그림 3에서 볼 수 있듯이 IG-img는 teacher filtering 후에 크게 불균형하기 때문에, 다음 실험에서는 IG-img를 GG-k400과 함께 사용
YoutubeVideo
- Youtube-car를 위한 video sharing platfomr 기반 web data source
- class 이름을 query하여 YouTube에서 28K 동영상을 크롤링
- de-duplicatin(중복 제거)(원래 Youtube-car 데이터 세트에서 비디오 제거) 및 teacher filtering 후 YT-car-17k로 표시하는 17K 비디오 사용
Experiments
[5.1 Video architectures]
주로 Temporal Segment Networks와 3D ConvNets라는 두 가지 video classification architecture families를 연구하여 설계의 효율성을 검증한다. 지정하지 않는 한 초기화를 위해 ImageNet pre-trained model을 사용한다. 우리는 MMAction을 사용하여 모든 실험을 한다.
2D TSN
- 원래 설정과 달리 달리 지정되지 않는 한 ResNet-50을 backbone으로 선택
- Segment 수는 Kinetics/UCF-101의 경우 각각 3개, Youtube-car의 경우 4개로 설정
3D ConvNets
- 대부분의 실험에서 SlowOnly 아키텍처를 사용
- 64개의 연속 프레임을 video clip으로 사용하고 4/8 프레임을 드물게 샘플링하여 네트워크 input을 형성
- scratch 학습을 하고 pre-trained model에서 fine-tuning하는 것을 포함하여 다양한 초기화 전략이 탐구
- Channel Separable Network와 같은 고급 아키텍처나 보다 강력한 pre-training (IG-65M)도 탐구
[5.2 Verifying the efficacy of OmniSource]
몇 가지 질문을 검토하여 프레임워크의 효율성을 확인합니다.
Why do we need teacher filtering and are search results good enough?
의문점 : Filtering을 위한 teacher network의 필요성
- 근거 : 최신 search engine이 검색 결과 생성을 돕기 위해 대규모 labeled data에 대해 학습된 visual recognition model을 내부적으로 활용했을 수 있다는 인상이 있음
- 주장 : web data가 본질적으로 noisy하고 반환된 결과의 거의 절반이 관련이 없음. 정량적으로 보면 web data의 70% - 80%가 teacher에 의해 제거된다. 반면, teacher filtering 없이 실험을 수행해보면, joint training을 위해 수집된 web data를 직접 사용하면 TSN에서 상당한(3% 이상) 성능 저하가 발생한다. 따라서 이는 크롤링된 web data에서 유용한 정보를 유지하면서 쓸모 없는 정보를 제거하는 데 teacher filtering이 필요함을 보여준다.
Does every data source contribute?
Images, Trimmed video 및 Untrimmed video와 같은 다양한 source type의 기여도를 살펴본다. 각 data source에 대해 auxiliary dataset를 구성하고 K400-tr과의 joint training에 사용한다. 표 13의 결과는 모든 source가 target task의 정확도 향상에 기여한다는 것을 보여준다. combine하면 성능이 더욱 향상된다.
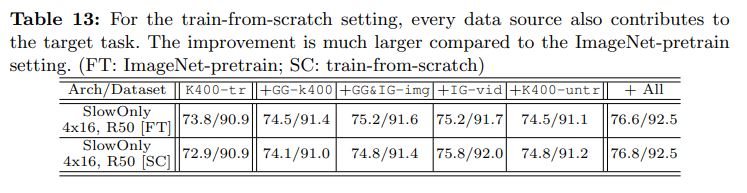
Image의 경우 GG-k400과 IG-img의 조합을 사용하면 Top-1 정확도가 약 1.4% 증가한다. Trimmed video의 경우 IG-vid에 중점을 둔다. 극도로 불균형하지만 IG-vid는 여전히 모든 설정에서 Top-1 정확도를 1.0% 이상 향상시킨다. Untrimmed video의 경우 Untrimmed Kinetics-400(K400-untr) 버전을 비디오 source로 사용하며 잘 작동하는 것으로 나타났다.
Do multiple sources outperform a single source?
의문점 : Multiple source의 web data가 target dataset에 공동으로 기여할 수 있음을 확인하면서 동일한 budget을 가진 single source보다 multiple source가 여전히 더 나은지 궁금
| 주장 : 이를 확인하기 위해서 K400-tr 및 $D_{A}$ = GG-k400 + IG-img 모두에서 TSN을 학습하는 경우를 고려해보자. Auxilary dataset의 스케일을 GG-k400의 스케일로 고정하고 GG-k400의 이미지를 IG-img의 이미지로 교체하여 GG-k400과 IG-img의 비율을 변경한다. 그림 4에서 $ | D_{A} | $ 를 증가시키지 않고 0.3%의 개선을 관찰했으며, 이는 multi source가 다양성을 도입하여 보완적인 정보를 제공함을 나타낸다. |
Does OmniSource work with different architectures?
우리는 광범위한 아키텍처에 대한 추가 실험을 수행하고 표 3의 결과를 얻었다. TSN의 경우 OmniSource가 Top-1 정확도를 1.9% 향상시키는 backbone으로 EfficientNet-B4[43]를 대신 사용한다. 3D-ConvNet의 경우 더 긴 input이 필요하고 더 큰 backbone을 갖는 SlowOnly-8x8-ResNet101 기준선에서 실험을 수행한다. 프레임워크는 이 경우에도 잘 동작하여 scratch training할 때 Top-1 accuracy를 76.3%에서 80.4%로, ImageNet pre-training을 통해 76.8%에서 80.5%로 개선한다. 더 큰 네트워크의 성능 향상은 더 높으며, 더 깊은 네트워크는 video data의 부족으로 고통받는 경향이 있으며 OmniSource가 이를 완화할 수 있음을 나타낸다.
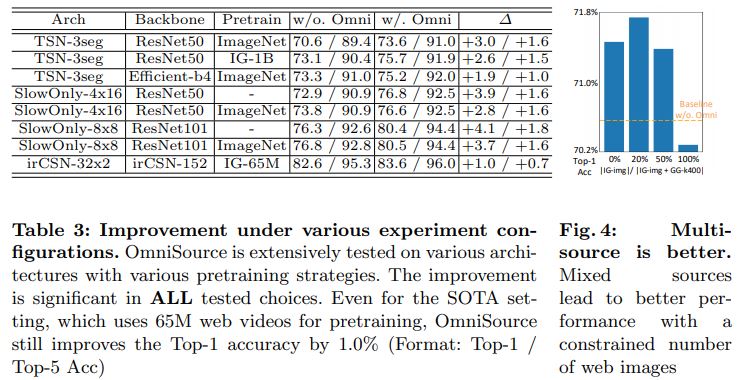
Is OmniSource compatible with different pre-training stategies?
논의한 바와 같이 OmniSource는 auxiliary data를 활용하여 데이터 부족 문제를 완화한다. 자연스러운 질문 중 하나는 “3D 네트워크를 scartch training할 때 성능이 어떤까?” 라는 질문이다. 보다 직접적인 training strategy를 추구하기 위해 ImageNet pre-training을 중단할 수 있는가? 실제로 OmniSource는 이 setting에서 상당히 잘 동작하며 흥미롭게도 성능 향상은 fine-tuning보다 더 중요하다. 예를 들어, SlowOnly-(4x16, R50)는 scratch training할 때 Top-1 정확도를 3.9% 증가시키는 반면 fine-tuning은 2.8%만 증가시킨다. Scratch training model은 OmniSource를 사용하여 fine-tuning model보다 0.2% 더 높지만 K400-tr만 사용하면 0.9% 더 낮다. SlowOnly-(8x8, R101)에서도 비슷한 결과를 볼 수 있다. 대규모 webly supervised pretraining을 통해 OmniSource는 여전히 상당한 성능 개선을 이끈다(TSN-3seg-R50의 경우 +2.6% Top-1, irCSN-32x2의 경우 +1.0% Top-1).
Do features learned by OmniSource transfer to other tasks?
OmniSource는 target video recognition task을 위해 설계되었지만 learned feature은 다른 video recognition task에도 잘 전달된다. Transfer capability을 평가하기 위해 상대적으로 작은 두 데이터 세트인 UCF101[41]과 HMDB51[24]에서 학습된 모델을 fine-tuning한다. 표 15는 두 benchmark 모두에서 OmniSource를 사용한 pre-trainnig이 상당한 성능 향상으로 이어진다는 것을 나타낸다. Standard evaluation protocol에 따라 SlowOnly-8x8-R101은 UCF101에서 97.3% Top1 정확도, RGB 입력이 있는 HMDB51에서 79.0% Top-1 정확도를 달성한다. optical flow과 결합하면 UCF101에서 98.6% 및 83.8% Top-1 정확도를 달성하고 새로운 state-of-the-art인 HMDB51다. Transfer learning에 대한 더 많은 결과는 supplementary material에서 제공한다.
Does OmniSource work in different target domains?
제안되는 프레임워크는 다양한 domain에서도 효과적이고 효율적이다. Youtube-car (fine-grained recognition benchmark) 를 위해서, 학습을 위한 50K web image(GG-car)와 17K web video(YT-car-17k)를 수집한다. 표 5는 성능 향상이 중요함을 보여준다. Top-1 정확도와 mAP 모두에서 5% 향상을 얻는다. UCF-101에서 BNInception을 백본으로 사용하여 2-stream TSN 네트워크를 학습한다. RGB stream은 GG-UCF를 사용 또는 사용하지 않고 학습된다. 결과는 표 6에 있다. RGB stream의 Top-1 정확도는 2.7% 향상된다. Flow stream과 융합될 때 여전히 1.1%의 향상이 있다.
Where does the performance gain come from?
Web data가 도움이 되는 이유를 알아보기 위해 수집된 Web dataset를 더 깊이 파고들어 개별 클래스의 개선 사항을 분석한다. 우리는 GG-k400을 사용 또는 사용하지 않고 학습된 TSN-3seg-R50을 선택한다. 여기서 개선은 평균 0.9% 이다. 우리는 주로 web image가 개선할 수 있는 confusion pair에 중점을 둔다. 우리는 class pair의 confusion score를 $s_{ij}$ = $(n_{ij} + n_{ji}) / (n_{ij} + n_{ji} + n_{ii} + n_{jj})$ 로 정의한다. 여기서 $n_{ij}$ 는 클래스 j로 인식되는 동안 ground-truth가 클래스 i인 이미지의 수를 나타낸다. 낮은 confusion score는 두 클래스 간의 더 나은 판별력을 나타낸다. 그림 5에서 몇 가지 confusing pair을 시각화한다. 우리는 개선이 주로 두 가지 이유에 기인할 수 있음을 발견했다.
- (1) Web data는 일반적으로 주요 작업 개체에 초점을 맞춤
- 예 : Confusion score 감소가 가장 큰 pair에서 “drinking beer” 대 “drinking shots” 및 “eating hotdog” 대 “eathing chips”와 같은 pair이 있음을 발견
- Web data를 사용한 학습은 일부 혼란스러운 경우에 더 나은 object recognition ability으로 이어짐
- (2) Web data에는 일반적으로 특히 짧은 시간 동안 지속되는 동작에 대해 차별적인 포즈가 포함
- 예 : “rock scissors paper” 대 “shaking hands”는 두 번째로 큰 confusion score reduction을 보임
- 예 : “sniffing”- “headbutting”, “break dancing”-“robot dancing” 등을 포함
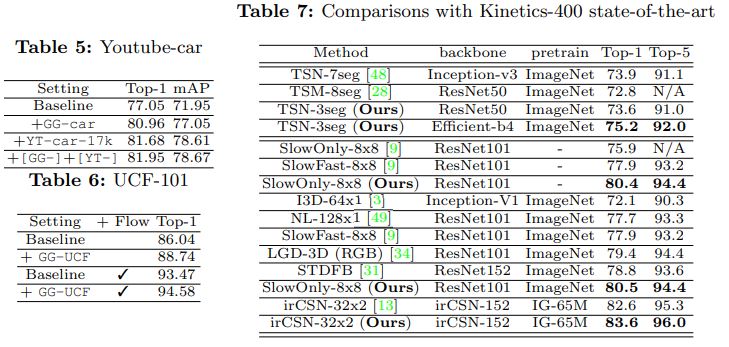
[5.3 Comparisons with state-of-the-art]
표 7에서는 OmniSource와 Kinetics400의 최신 기술을 비교한다. 2D ConvNet의 경우 더 적은 수의 segment와 더 가벼운 백본으로 경쟁력 있는 성능을 얻는다. 3D ConvNet의 경우 OmniSource가 적용된 모든 pre-training setting에서 상당한 개선이 이루어졌다. IG-65M 사전 훈련된 irCSN-152를 통해 OmniSource는 83.6%의 Top-1 정확도, 1.2%의 상대적으로 더 많은 데이터로 1.0%의 절대 개선을 달성하여 새로운 기록을 수립한다.
[5.4 Validating the good practices in OmniSource]
몇 가지 ablation experiment 수행. Target dataset는 K400-tr이고 auxiliary dataset는 지정하지 않는 한 GG-k400다.
Transforming images to video clips.
표 8에서 Web image를 clip으로 변환하는 다양한 방법을 비교한다. Still image를 순조롭게 복제하는 것은 제한적인 개선(0.3%)을 가져온다. 그런 다음 무작위 또는 일정한 속도로 translation을 적용하여 pseudo clip을 형성한다. 그러나 성능이 약간 저하되어 translation이 카메라 모션을 잘 모방할 수 없다. 마지막으로 카메라 모션을 hallucinate하기 위해 perspective warping에 의존한다. Class-agnostic distribution parameter를 추정하는 것이 약간 더 나은데, 이는 모든 비디오가 유사한 카메라 모션 statistics를 공유할 수 있음을 시사한다.
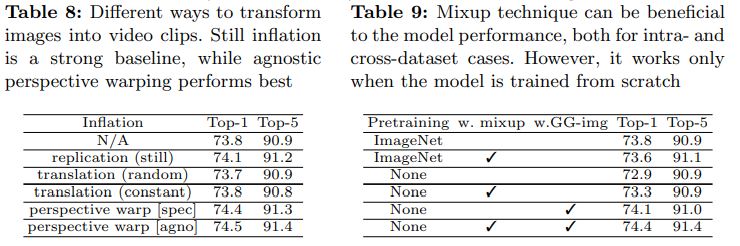
Cross-Dataset mixup
표 9에서 우리는 모델이 scratch training될 때 intra- 및 cross-dataset의 경우 모두에서 mixup이 video recognition에 효과적이라는 것을 발견했다. Fine-tuning에 대한 효과는 불분명하다. 특히, mixup은 intra- 및 inter-dataset 간 사례에 대해 0.4% 및 0.3% Top-1 정확도 향상으로 이어질 수 있다.
Impact of teacher choice.
교사와 학생 네트워크는 모두 2D 또는 3D ConvNet일 수 있으므로 teacher network 선택에는 4가지 가능한 조합이 있습니다. 이미지의 경우
- 3D ConvNet을 2D로 축소하면 성능이 크게 저하되서 web image에는 3D ConvNet teacher를 사용하지 않음
비디오의 경우 - 3D ConvNet은 2D에 비해 더 나은 필터링 결과를 제공
- 다른 teacher의 효과를 조사하기 위해 student 모델을 ResNet-50으로 수정하고 teacher 모델(ResNet-50, EfficientNet-b4, ResNet-152 및 EfficientNet-b4의 앙상블)의 선택을 다양화
- baseline(70.6%)에 대해 일관된 개선이 관찰되었다. 더 나은 teacher network를 사용하면 studnet 정확도가 높아진다. Web video의 3D ConvNet에도 적용된다.
Effectiveness when labels are limited.
Limited labeled data의 유효성을 검증하기 위해 우리는 각각 3%, 10% 및 30%의 비율로 K400-tr의 3개 subsets을 구성합니다. Weaker teacher로 data filtering을 포함하여 전체 프레임워크를 다시 실행한다. K400-tr의 validation set에 대한 최종 결과는 그림 7에 있다. 우리의 프레임워크는 labeled video의 비율이 다양함에 따라 지속적으로 성능을 향상시킨다. 특히, gain은 데이터가 부족할 때 더 중요하다. (3% labeled data로 30% 이상의 상대적 증가.)
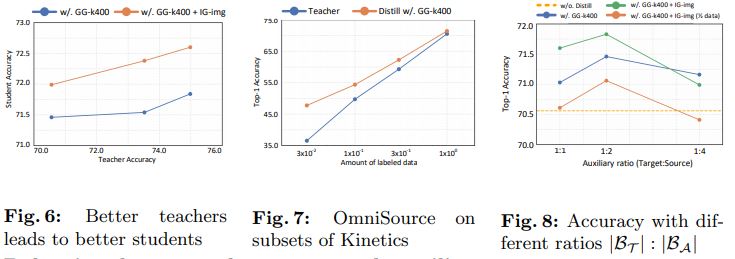
Balancing between the target and auxiliary dataset.
Target dataset | $B_{T}$ | 와 Auxiliary dataset | $B_{A}$ |의 batch size 사이의 비율을 조정하여 그림 8에서 정확도를 얻는다. 우리는 3가지 시나리오를 테스트한다.
- (1) Sec 4.2절에 명시된 원본 GG-k400
- (2) [GG+IG]-k400, GG-k400과 IG-img의 union
- (3) (2)의 절반인 [GG+IG]-k400-half
대부분의 경우, | $B_{T}$ | / | $B_{A}$ |를 선택하면 성능 이득이 강력하다는 것을 알 수 있다. 그러나 Auxiliary data가 적으면 비율을 더 신중하게 처리해야 한다. 예를 들어, 더 작은 | $D_{A}$ | 과 더 큰 | $B_{A}$ | 은 auxiliary sample을 과적합하여 전체 결과를 손상시킬 수 있다.
Resampling strategies.
Target dataset은 일반적으로 클래스 간에 균형을 이룬다. 좋은 property는 반드시 auxiliary dataset에 대해 유지되지 않기 때문에, 몇 가지 resampling strategy를 제안한다. 표 10에서 우리는 distribution을 보다 균형 잡힌 distribution으로 조정하는 간단한 기술이 좋은 개선을 가져온다는 것을 알 수 있다.

Conclusion
- webly-supervised video recognition을 위한 간단+효과적인 프레임워크인 OmniSource를 제안
- 제안된 방법은 multiple source와 format의 web data를 동일한 형식으로 변환하여 활용할 수 있음
- 제안된 task-specific data collection은 데이터 효율성이 높음
- 프레임워크는 다양한 비디오 작업에 적용할 수 있으며, pretraining strategy의 모든 설정에서 여러 벤치마크에서 state-of-the-art를 얻음
Appendix
Appendix에는 실험 세부사항과 분석이 설명되어 있음.
Leave a comment