PERF-Net : Pose Empowered RGB-Flow Net 리뷰
Updated:
PERF-Net : Pose Empowered RGB-Flow Net 리뷰
논문 다운 링크
https://arxiv.org/pdf/2009.13087.pdf
Abstract
최근 몇 년동안, 비디오 action recognition 문헌의 많은 연구에서 최첨단 성능을 달성하려면 두 가지 스트림 모델 (공간 및 시간 input stream 결합)이 필요하다는 사실이 밝혀졌다.
이 paper에서는
- 입력 RGB frame에서 pose를 렌더링하여 각 프레임에서 추정된 사람 pose를 기반으로 한 또 다른 stream을 포함하는 이점을 보여줌
- 처음에는 사람의 자세가 RGB 픽셀 값에 의해 완전히 결정된다는 점을 감안할 때이 추가 스트림이 중복된 것처럼 보일 수 있지만, 이 단순하고 유연한 추가가 보완적인 이득을 제공할 수 있다는 것을 보여줌
- PERF-Net (Pose Empowered RGB-Flow Net의 약자)이라고하는 모델을 제안
- distillation 기술을 통해 이 새로운 포즈 스트림을 표준 RGB 및 flow 기반 입력 스트림과 결합
- 모델은 inference time에 명시적으로 계산할 흐름이나 자세를 요구하지 않으면서 많은 인간 action recognition 데이터 세트에서 최신 기술을 능가
Introduction
2-stream framework에 pose stream을 추가하는 방식 제안
- 근거
- action dataset은 인간 중심적인 경향이 있음
- 따라서, pose que가 있으면 raw pixel이나 flow 추론이 더 간단할 수 있음
- 주의해야 할 것은 RGB frame 위에 pose를 렌더링하여 pose signal과 주변 상황의 qeu를 모두 활용

D3d : Distilled 3d networks for video action recognition (IEEE 2020) 에서 영감을 받았음
- Temporal stream 의 이점을 distillation training 을 통해 RGB-only model로 capture하여 inference time에 redundant input stream의 필요성을 없앨 수 있음을 보여줌
Pose 와 Flow 문제에도 distillation technique 적용하여 self-gating based architecture와 결합하여 flow 나 pose 를 계산하지 않아도 되는 RGB-only model을 얻을 수 있음
Contribution
- 비디오 action 에서 pose 의 중요성과 RGB 와 Flow stream 에 대한 보완적인 input stream 이 됨을 증명
- PERF-Net 제안 (multi-teacher distillation setting에서 RGB, Flow, Pose input stream 활용)
- frame collection 내의 pose 정보와 RGB 사이의 gap을 줄일 수 있는 context-aware human pose rendering 제안
Related work
Fusion of multiple modalities
- 별도로 학습시킨 2개의 2D CNN (RGB와 optical flow)
- Temporal pattern 을 직접 modeling하도록 3D ConvNet 학습 (예 : I3D)
- 2-stream , 모두 RGB 입력, 다른 frame 속도 ( Slowfast Net)
- 모두 RGB or optical flow를 학습
본 논문은 3D CNN의 input stream 으로 사람의 pose 를 가장 잘 표현하는 방법에 중점
Distillation between modalities
- 많은 computational cost 의 multi-stream model
- Distillation model을 사용한 모델
- Zhang et al. (2016) : optical flow에 대해 학습된 teacher model, 입력이 motion vector인 student model
- Stroud (2020) , Crasto (2019) : flow stream 을 RGB stream 으로 distillation
Pose Empowered RGB-Flow Nets (PERF-Net)
일반적으로 사용하는 2-stream 에 pose stream 을 추가하는 방법
- 정확하지만 3D convNet 을 여러 번 실행해야 하기 때문에 매우 느림
PERF-Net
- Multi-teacher distillation을 사용하여
- 학습 시간에는 RGB, Flow, Pose modality 모두 사용
- Inference time에는 RGB만 사용하는 모델
Pose representation
- PoseNet으로 17개 pose keypoint 추출
- COCO dataset으로 pre-train 된 ResNet backbone
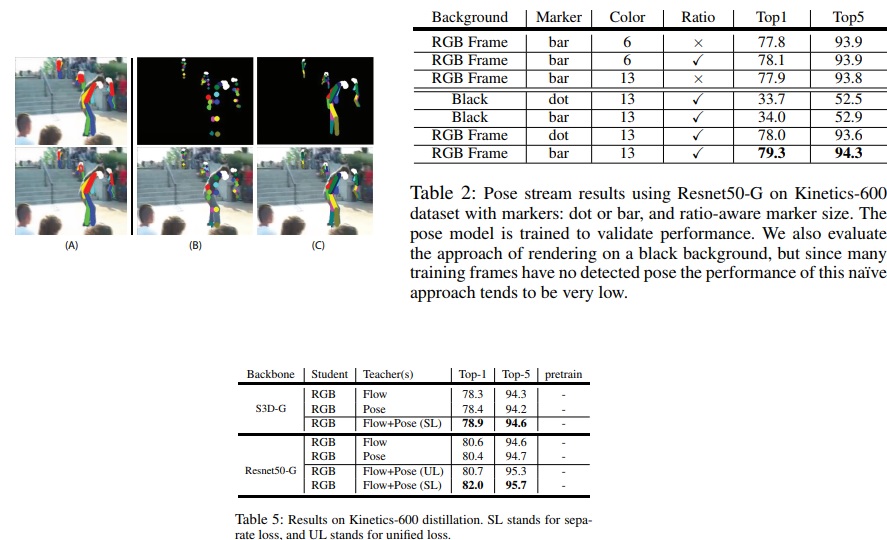
Pose를 frame으로 rendering 하는 방법
- 기존
- 검정 배경에 rendering
- 세 가지 실험
- Dots vs. Bars
- Fine vs. Coarse-grained coloring
- Uniform vs. Ratio-aware line thickness

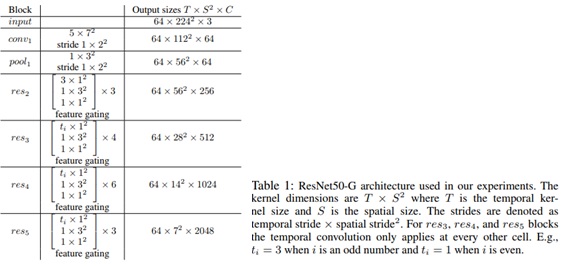
Backbone architecture
- “Inflated” 된 3D version의 ResNet-50
- 모든 max pooling 제거
- 모든 layer에서 temporal downsampling의 적용이 성능 저하에 영향
- 각 Residual block 다음에 feature gating module 추가
- Context 기반으로 channel 에 weight 를 다시 부여하는 self-attention mechanism
- 이거를 ResNet50-G라고 함
하지만 pose 를 input stream 으로의 사용은 backbone 선택에 의존하지 않음
- 여기서는 S3D-G backbone을 사용
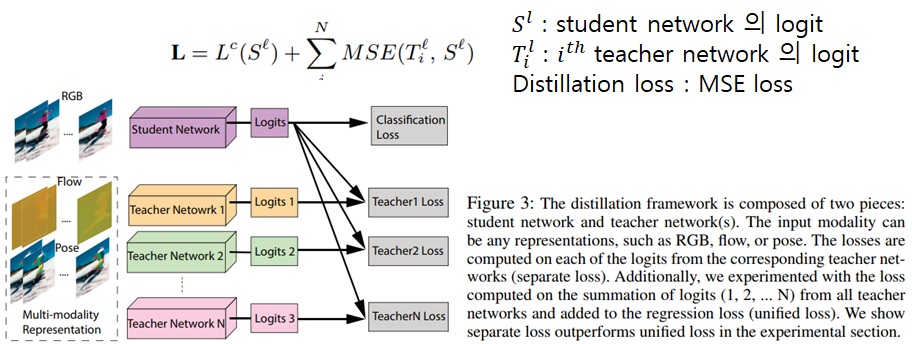
Multi-stream fusion via distillation
- RGB, Flow, Pose 를 기반으로 3개의 모델을 학습했다고 가정
- Distillation approach 방식의 목표
- 3개의 모델의 장점을 capture 하면서 계산량이 적은 RGB-only model 을 학습시키는 것
Loss
- Student model이 각 teacher network 의 logit 을 모방함과 동시에 backpropagation 을 통해 GT label의 loss를 최소화
Experiments
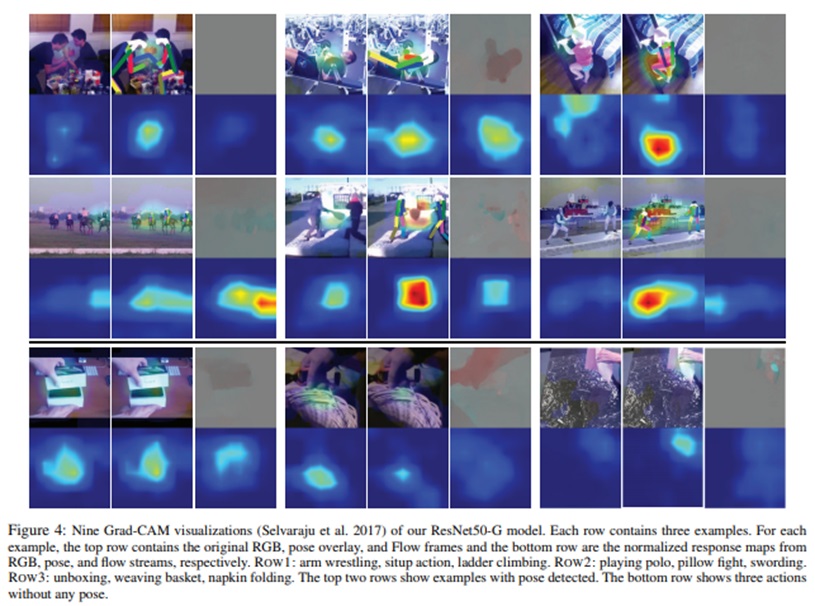
Conclusion
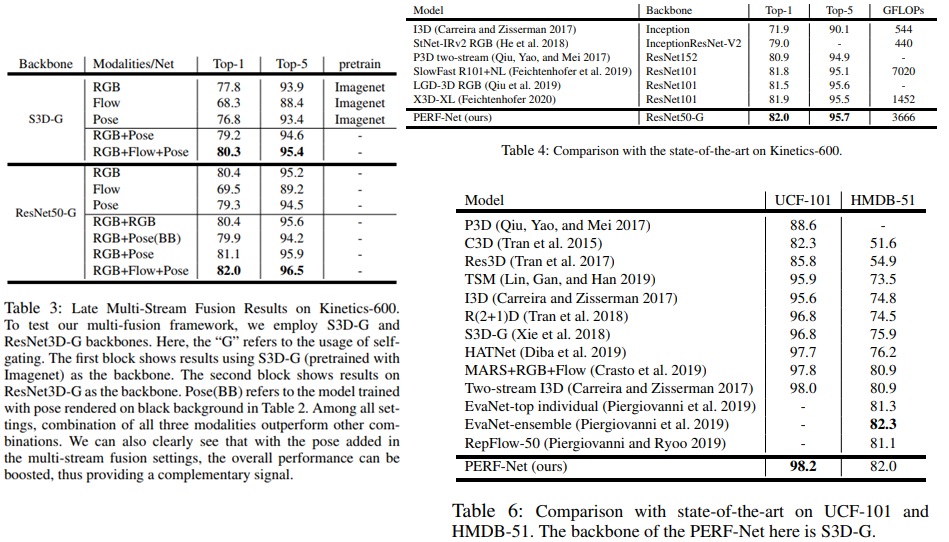
우리는 다양한 pose 렌더링 방법의 효과에 대한 실증적 연구와 이를 비디오 인식 모델에 효과적으로 통합하여 사람의 행동 인식에 도움이 되는 방법을 제시했다. 우리는 human pose modality와 제안된 렌더링 방법으로 간단한 fusion 방법을 사용하여 모델이 state-of-the-art를 능가할 수 있다는 강력한 증거를 보여주다. 우리는 그러한 pose modality가 다른 domain으로 확장되기 위해 더 연구될 수 있기를 바란다.
Leave a comment