Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs 리뷰
Updated:
Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs 리뷰
Google Research 에서 나온 논문이고 현재 아카이브에만 등록되어있습니다. Mediapipe에서 facial landmark를 추출과 관련된 논문입니다.
논문 다운 링크
https://arxiv.org/abs/1907.06724
Abstract
End-to-end neural network-based model 소개
- AR app 을 위한 single camera input 에서 human face 의 대략적인 3D mesh representation 을 추론
468개의 vertices 로 구성된 비교적 조밀한 mesh model은 얼굴 기반 AR 효과에 적합
제안된 모델
- mobile GPU에서 super-realtime inference speed(장치 및 모델 변형에 따라 100~1000FPS 이상)
- 동일한 이미지의 manual annotation 의 variance 에 필적하는 높은 예측 품질을 보여줌
Introduction
Face alignment 또는 face registration 라고도 하는 facial mesh template 을 정렬하여 facial geometry 를 예측하는 문제는 오랫동안 컴퓨터 비전의 초석이었다. 일반적으로 68개의 랜드마크(키포인트)를 찾는 데 사용한다. 이러한 point 는 고유한 의미를 갖거나 meaningful facial contour 에 participate 한다. 2D 및 3D face alignment 문제에 대한 관련 작업에 대한 좋은 검토를 위해 [4] 논문을 참조하는 걸 권한다.
대안적인 접근 방식은 3D morphable model(3DMM)[3]의 pose, scale 및 parameter를 추정하는 것이다. Basel Face Model[7]의 2017년 판인 BFM2017과 같은 3DMM은 일반적으로 PCA를 통해 얻는다. 결과 메쉬는 일반적으로 더 많은 point(BFM의 경우 약 50K)을 특징으로 하지만 가능한 예측 범위는 PCA 기반에 의해 확장되는 linear manifold 에 의해 제한되며, 이는 캡처된 모델을 위해 얼굴 세트의 다양성에 의해 차례로 결정된다. 구체적인 예로서, BFM은 정확히 한쪽 눈을 감고 있는 얼굴을 안정적으로 표현할 수 없는 것처럼 보인다.
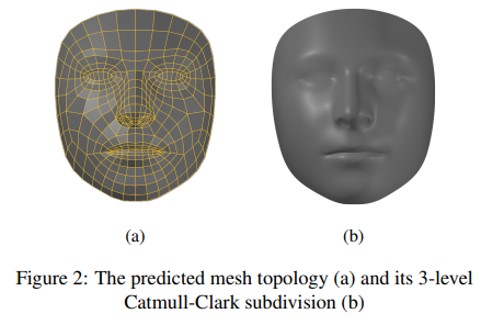
본 논문에서는 각 vertex 를 독립적인 랜드마크로 취급하여 신경망으로 3D mesh vertices의 위치를 추정하는 문제를 제시한다. Mesh topology 는 fixed quads 로 배열된 468개의 포인트로 구성한다 (그림 2a 참조).
포인트는 표현력이 풍부한 AR 효과, 가상 액세서리 및 의류 시착 및 메이크업과 같은 응용 프로그램에 따라 수동으로 선택되었다. 인간 지각에서 더 높은 가변성과 더 높은 중요성을 가질 것으로 예상되는 영역은 더 높은 포인트 밀도로 할당되었다. CatmullClark subdivision[6] (그림 2.b)를 적용하여 그럴듯한 매끄러운 표면 표현을 구축할 수 있다.
모델에 대한 입력 : 단일 RGB 카메라의 프레임 (depth sensor 정보가 필요하지 않음)
모델 출력의 예 : 그림 1
- 우리의 설정은 실시간 모바일 GPU 추론을 목표로 하지만 적절한 GPU 지원이 부족한 모바일 장치에서 CPU 추론을 해결하기 위해 더 가벼운 버전의 모델도 설계
실험에서 CPU에 맞게 조정된 “lightest” 모델과 대조하여 GPU 타겟팅 모델을 “full” 모델이라고 정의.

Image processing pipeline
논문에서는 다음과 같이 이미지 처리를 구성 :
-
카메라 입력의 전체 프레임은 얼굴 경계 직사각형과 여러 랜드마크(예: 눈의 중심, 귀, 코끝)를 생성하는 very lightest face detector[2:BlazeFace]에 의해 처리된다. 랜드마크는 안면 직사각형을 회전하여 눈 중심을 직사각형의 수평 축과 연결하는 선을 정렬하는 데 사용한다.
-
이전 단계에서 얻은 사각형은 원본 이미지에서 crop되고 size 조정되어 mesh prediction nerual entwork에 대한 입력으로 구성한다(full 모델의 경우 256×256 픽셀부터 smallest 모델의 경우 128×128 픽셀까지). 이 모델은 3D landmark coordinates 의 벡터를 생성하고 이후에 original image coordinate system으로 다시 매핑한다. 별개의 scalar network 출력(face flag)은 제공된 crop에 합리적으로 정렬된 face가 실제로 존재할 확률을 생성한다.
Vertex 의 x, y 좌표가 이미지 픽셀 좌표에 의해 제공된 2D 평면의 점 위치에 해당하는 policy 채택. z 좌표는 mesh 의 질량 중심을 통과하는 reference plane 에 상대적인 깊이로 해석. x 좌표의 범위와 z 좌표의 범위 사이에 고정된 aspect ratio 가 유지되도록 크기가 다시 조정. 즉 ,크기의 절반으로 축소된 얼굴은 depth range(가장 가까운 것부터 가장 먼 것까지)를 동일한 배율로 축소.
Face tracking mode 에서 비디오 입력에 사용하면, previous frame prediction 에서 good facial crop 을 사용할 수 있고 + face detector의 사용이 중복됨. 이 시나리오에서는, 첫 번째 프레임과 드물게 재획득하는 경우에만 사용 (face flag 에 의해 예측된 확률이 적절한 임계값 아래로 떨어진 후).
Vertex 의 x, y 좌표가 image pixel coordinate에 의해 제공된 2D plane의 점 위치에 해당하는 policy 채택하였다. z 좌표는 mesh 의 질량 중심을 통과하는 reference plane 에 상대적인 깊이로 해석한다. x 좌표의 범위와 z 좌표의 범위 사이에 고정된 aspect ratio 가 유지되도록 크기가 다시 조정한다. 즉, 크기의 절반으로 축소된 얼굴은 depth range(가장 가까운 것부터 가장 먼 것까지)를 동일한 배율로 축소한다.
Face tracking mode 에서 비디오 입력을 사용하면, previous frame prediction 에서 good facial crop 을 사용할 수 있고 face detector의 사용이 중복된다. 이 시나리오에서는, 첫 번째 프레임과 드물게 재획득하는 경우에만 사용한다(face flag 에 의해 예측된 확률이 적절한 임계값 아래로 떨어진 후).
이 setup에서는 두 번째 네트워크는 face가 중앙에 적절하게 정렬되고 정렬된 입력을 수신한다는 점에 유의해야 한다. 우리는 이것이 상당한 회전 및 변환으로 케이스를 처리하는 데 소비될 수 있는 일부 model representational capacity을 절약할 수 있다고 주장한다. 특히, prediction quality 를 얻으면서 관련 augmentation의 양을 줄일 수 있었다.
Dataset, annotation, and training
Dataset
학습에서, 변화하는 조명 조건에서 다양한 센서에서 찍은 약 30,000개의 야생 모바일 카메라 사진의 전 세계적으로 소싱된 데이터 세트에 의존한다. 학습 동안 standard cropping 및 image processing primitives 와 몇 가지 전문화된 primitives 를 사용하여 데이터 세트를 추가로 보강하였다.
- modelling camera sensor noise[8] 및 image intensity histogram에서 randomized non-linear parametric transformation 적용(후자는 주변 조명 시뮬레이션에 도움)
Annotation
468개의 3D mesh points 에 대한 기본 정보를 얻는 것은 노동 집약적이고 매우 모호한 작업이다. 포인트를 하나씩 수동으로 주석을 추가하는 대신 다음과 같은 반복 절차를 사용합니다.
Training
절차 1. 아래의 두 가지 supervision source를 사용하여 초기 모델을 학습시킴
- 실제 사진의 얼굴 직각에 대한 3DMM의 합성 렌더링을 한다(예: 단색 배경과 대조하여 과적합을 방지).따라서 실제 정점 좌표는 468개의 mesh point와 3DMM vertices의 하위 집합 간의 predefined correspondence에서 즉시 사용할 수 있다.
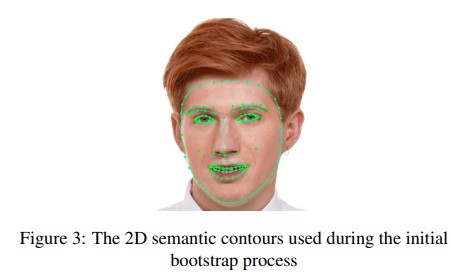
- 실제 “in-the-wild” 데이터 세트에 주석이 달린 일련의 sementic contours(그림 3 참조)에 참여하는 mesh vercies의 작은 하위 집합에 해당하는 2D 랜드마크. 랜드마크는 2D와 3D path 사이의 Intermediate face representation을 공유하기 위해 도입된 dedicated network branch의 끝에서 별도의 출력으로 예측된다.
이 첫 번째 모델이 학습된 후, 데이터 세트에 있는 이미지의 최대 30%가 후속 단계에서 refinement에 적합한 예측을 가진다.
절차 2. 이미지에 최신 모델을 적용하여 부트스트랩된 x 및 y 좌표를 반복적으로 수정하고 이러한 미세 조정에 적합한 항목을 필터링한다. (예: 예측 오류가 허용되는 경우)
- 전체 범위의 포인트를 한 번에 이동할 수 있도록 반경을 조정할 수 있는 “brush” 도구를 통해 빠른 주석 수정이 가능
- 이동량은 마우스 커서 아래의 pivot vertex에서 메쉬 가장자리를 따라 거리에 따라 기하급수적으로 감소
- 이를 통해 annotator는 메시 표면의 부드러움을 유지하면서 local refinements 전에 큰 “strokes”로 상당한 영역 변위를 조정할 수 있다.
- z 좌표는 그대로 유지
- 이들에 대한 supervision의 유일한 출처는 위의 요약된 합성 3D 렌더링이다. 따라서 depth prediction이 미터법적으로 정확하지 않음에도 불구하고 우리의 경험에 따르면 결과 메시는 예를 들어 다음과 같이 시각적으로 그럴듯하다. 얼굴에 사실적인 3D texture rendering을 구현하거나 가상 액세서리 시착 경험의 일부로 렌더링된 3D 개체를 정렬할 수 있다.
Model architecture
mesh prediction model의 경우 사용자 지정이지만 상당히 간단한 residual neural network architecture를 사용한다. network의 초기 layer에서 보다 적극적인 subsampling을 사용하고 대부분의 계산을 shallow part에 할애한다.
따라서, neuron receptive field는 비교적 일찍 input image의 넓은 영역을 덮기 시작한다. 이러한 receptive field가 image boundary에 도달하면 input image의 상대 위치가 모델에서 암시적으로 사용할 수 있게 된다(convolution padding으로 인해). 결과적으로, 더 깊은 layer에 대한 neuron은 예를 들어 입 관련 기능과 눈 관련 기능을 구별할 가능성이 높다.
model은 image boundary를 약간 가리거나 교차하는 face을 완성할 수 있다. 이것은 high-level 및 low-level mesh representation이 네트워크의 마지막 몇 layer에서만 좌표로 바뀌는 모델에 의해 구축된다는 결론에 이르게 한다.
Filtering for temporal consistency in video
our model은 single-frame level에서 동작하기 때문에 프레임 간에 전달되는 유일한 정보는 회전된 facial bounding rectangle(및 face detector로 re-evaluated 여부)다.후속 video frame에서 얼굴의 pixel-level image representataions의 불일치 때문에(small affine transforms of the view, head pose change, lighting variation 및 diffent kinds of camera sensor noise[8]로 인해), 이는 개별 랜드마크의 trajectory에서 human-noticeable fluctuations 또는 temporal jitter(표면으로서의 전체 메시는 이 현상의 영향을 덜 받는다).
예측된 각 랜드마크 좌표에 독립적으로 적용되는 1차원 temporal filter를 사용하여 이 문제를 해결할 것을 제안한다. 제안한 파이프라인의 주요 응용 프로그램은 시각적으로 매력적인 렌더링이므로 human-computer interaction methods, 특히 1 Euro filter[5]에서 영감을 얻었다. 1 Euro 및 관련 filter의 주요 전제는 noise 감소와 phase lag elimination 사이의 trade-off에서 변화율이 더 높을 때, 인간은 매개변수가 사실상 변경되지 않을 때 전자(즉, 안정화)를 선호하고 후자(즉, 지연 방지)를 선호한다는 것이다. 우리의 필터는 velocity estimation을 위해 몇 개의 타임스탬프가 찍힌 샘플의 고정 rolling window를 유지하며, 비디오 스트림의 얼굴 크기 변경을 수용하기 위해 얼굴 크기로 조정된다.이 필터를 사용하면 눈에 띄는 jitter 없이 비디오에서 사람이 좋아하는 예측 시퀀스를 얻을 수 있다.
Results
prediction과 실제 vertex 사이의 mean absolute distance(MAD)를 사용하며, interocular distance(IOD)로 normalization되며, 눈 중심 사이의 거리로 정의된다(시선 방향 의존성을 피하기 위해 세그먼트를 연결하는 눈 모서리의 중간점으로 추정).이 normalization은 얼굴 크기를 고려하지 않는 것을 목표로 한다. z 좌표는 synthetic supervision에서 독점적으로 얻어지기 때문에 2D-only error를 보고하지만 가능한 yaw head rotation을 설명하기 위해 3D 안구간 거리(IOD)가 사용된다.
문제의 모호성을 수량화하고 metric의 기준선을 얻기 위해 58개의 이미지 세트에 11명의 훈련된 주석자 각각에 주석을 달고 동일한 이미지의 주석 사이에 IOD normalization MAD를 계산하는 작업을 제공했다.추정된 IOD MAD 오류는 2.56%였다.
1.7K 이미지의 geographically로 다양한 평가 세트에 대한 평가 결과를 제시한다. velocity estimation은 TensorFlow Lite GPU framework[1]를 기반으로 한다.
이 논문에서 설명하는 기술은 mobile에서 major AR self-expression applicaion 및 AR developer API를 구동하고 있다. 그림 4는 이를 통해 활성화된 다양한 렌더링 효과의 두 가지 예를 보여준다.

Leave a comment