SlowFast Networks for Video Recognition 리뷰
Updated:
SlowFast Networks for Video Recognition 리뷰
논문 다운 링크
https://arxiv.org/pdf/1812.03982.pdf
Abstract
SlowFast Network를 소개한다.
구성은 크게 2가지로
(i) Slow pathway
- low frame에서 동작하며 spatial semantics를 capture
(ii) Fast pathway
- cahnnel capacity를 줄임으로써 lightweight를 가지면서 video recognition에서 유용한 temporal information을 학습 가능
이다.
제안된 SlowFast Network에서
- 비디오의 action classification과 detection 에서 좋은 성능
- 해당 분야에서 큰 개선 사항을 정확히 지적
했다고 말한다.
사용한 Dataset : Kinetics, Charades, AVA dataset
Github 주소 : https://github.com/facebookresearch/SlowFast
Introduction
이미지 I(x, y)를 인식할 때 두 공간 차원 x 및 y를 대칭으로 처리하는 것이 일반적이다. 이것은 첫 번째 approximation isotropic(모든 orientation(방향)이 동일할 가능성이 있음) 및 shift-invariant에 해당하는 자연 이미지의 통계에 의해 정당화된다. 하지만 비디오 신호 I(x, y, t)는 어떤가? motion은 방향의 시공간적 대응이지만 모든 시공간적 방향은 동일하지 않다. Slow motion은 빠른 동작보다 가능성이 더 높으며 (실제로 우리가 보는 대부분의 세계는 주어진 순간에 휴식을 취하고 있음) 이것은 인간이 motion stimuli(모션 자극)를 인식하는 방식에 대한 Bayesian account에서 활용되었다. 예를 들어, 움직이는 가장자리를 분리하여 볼 경우 원칙적으로 자체에 접하는 임의의 이동 구성 요소 (optical flow의 aperture(조리개) 문제)를 가질 수도 있지만, 그 자체에 수직으로 움직이는 것으로 인식한다. 이 지각은 prior favor가 느린 movement를 선호한다면 합리적이다.
모든 시공간적 orientation이 같지 않다면 시공간적 convolution을 기반으로 한 비디오 인식 접근 방식에서 암시하는 것처럼 공간과 시간을 대칭적으로 처리할 이유가 없다. 대신, 공간 구조와 시간적 이벤트를 개별적으로 처리하기 위해 아키텍처를 “factor”할 수 있다. 구체적으로 recognition의 맥락에서 이것을 연구해보자. visual content의 categorical spatial semantics는 종종 천천히 변한다. 예를 들어, 손을 흔드는 것은 손을 흔들면서 자신의 정체성을 “손”으로 변경하지 않으며, 사람은 걷기에서 달리기로 이동할 수 있더라도 항상 “사람” 범주에 속한다. 따라서 categorical semantics(색상, 질감, 조명 등)의 인식은 상대적으로 느리게 새로 고쳐질 수 있다. 반면에 motion은 clapping, waving, shaking, walking, jumping 같이 피사체의 정체성보다 훨씬 빠르게 변화할 수 있다. fast refreshing frames(high temporal resolution)을 사용하여 잠재적으로 빠르게 변화하는 모션을 효과적으로 모델링하는 것이 좋다.
이러한 직관을 바탕으로 비디오 인식을 위한 two-pathway SlowFast 모델을 제시한다(그림 1). 하나의 pathway는 images 또는 few sparse 프레임에서 제공 할 수 있는 semantic information을 capture하도록 설계되었으며 low frame rates와 slow refreshing speed로 작동한다. 반대로, 다른 pathway는 fast refreshing와 high temporal resolution으로 작동하여 빠르게 변화하는 motion을 capture하는 역할을 한다. high temporal rate에도 불구하고 이 path는 전체 계산의 ~ 20%와 같이 매우 가벼운 weight를 갖는다. 이는 이 path가 공간 정보를 처리하는 더 적은 수의 channel과 weaker ability을 갖도록 설계되었지만, 이러한 정보는 덜 중복되는 방식으로 첫 번째 path에 의해 제공될 수 있기 때문이다. 우리는 첫 번째를 Slow pathway, 두 번째는 서로 다른 시간적 속도에 의해 구동되는 Fast pathway라고 부른다. 두 pathway는 lateral connection으로 fusion된다.
우리의 conceptual idea는 비디오 모델을 위한 유연하고 효과적인 디자인으로 이어진다. Fast pathway는 lightweight 특성으로 인해 temporal pooling을 수행할 필요가 없다. 모든 중간 layer에 대해 높은 프레임 속도로 동작하고 temporal fidelity를 유지할 수 있다. 한편, lower temporal rate 덕분에, Slow pathway는 spatial domain and semantics에 더 집중할 수 있다. raw video를 다른 시간 rate로 처리함으로써 우리의 방법은 두 pathway가 비디오 모델링에 대한 자체 전문지식을 가질 수 있도록 한다.
2-stream design을 가지고 있지만 개념적으로 다른 관점을 제공하는 잘 알려진 아키텍처가 있다. Two-Stream 방법은 우리 방법의 핵심 개념인 다른 temporal speed의 잠재력을 탐구하지 않았다. 2-stream 방법은 두 스트림에 동일한 backbone 구조를 채택하는 반면, Fast 경로는 더 가볍다. 우리의 방법은 optical flow를 계산하지 않으므로 모델은 raw data에서 end-to-end 학습이 된다. 실험에서 우리는 SlowFast 네트워크가 더 효과적이라는 것을 관찰했다.
우리의 방법은 영장류 시각 시스템의 망막 신경절 세포에 대한 생물학적 연구에서 부분적으로 영감을 얻었다. 이 연구는 이 세포에서 ~ 80%가 Parvocellualr (P-cells)이고 ~ 15-20%가 Magnocellualr(M-cells)라는 것을 발견했다. M-cells는 높은 temporal frequency에서 동작하며 빠른 temporal changes에 반응하지만, spatial detail or color에는 민감하지 않다. P-cells는 미세한 spatial detail and color를 제공하지만 temporal resolution이 낮아 자극에 느리게 반응한다. 우리의 프레임 워크는 다음과 같은 점에서 유사하다.
- (i) 우리 모델은 낮은 temporal resolution과 높은 temporal resolution에서 별도로 동작하는 두 가지 pathway를 가지고 있다.
- (ii) 우리의 Fast pathway는 빠르게 변화하는 motion을 캡처하지만 M-cells와 유사한 spatial detail은 더 적게 capture하도록 설계되었다.
- (iii) 우리의 Fast pathway는 M-cells의 small ratio와 비슷하게 가볍다.
이러한 관계가 video recognition을 위한 더 많은 computer vision model에 영감을 줄 수 있기를 바란다.
Kinetics-400, Kinetics-600, Charades 및 AVA 데이터 세트에 대한 방법을 평가한다. Kinetics action classificafion에 대한 comprehensive ablation experiment는 SlowFast가 기여한 효능을 보여준다. SlowFast 네트워크는 문헌의 이전 시스템에 비해 상당한 이점을 제공하면서 모든 데이터 세트에 sota를 달성했다.
Related Work
Spatiotemporal filtering.
- Action은 spatiotemporal object 로 formulate 될 수 있으며, spacetime 에서 oriented filtering 을 통해 capture 될 수 있음
- 3D Convolution Network 는 2D image model 을 시공간 영역으로 확장하여 처리하는 방법
- Temporal stride를 사용하는 long-term filtering 및 pooling에 초점을 맞춘 방법
- 2D spatial 과 1D temporal filter로 분해하는 방법
위의 방식들과 달리 본 논문에서는 두 가지 다른 temporal speed 를 사용하여 modeling 하는 것에 초점을 두었음
Optical flow for video recognition.
- 고전적인 방식으로 optical flow를 기반으로 하는 방식
- flow histogram, flow edge histogram 등의 방법들은 deep learning 이전의 방식들
Deep leaning 에서는 다른 input stream 으로 활용하였지만 end-to-end 학습이 이뤄지지 않는 점에서 방법론적으로 저자는 만족스럽지 않다고 주장
SlowFast Networks
제안하는 SlowFast Network는 두 개의 서로 다른 프레임 속도에서 동작하는 single stream 아키텍처로 볼 수 있지만 저자는 생물학적 Parvo 및 Magnocellualr counterpart 와의 유사성을 반영하기 위해서 pathway 개념을 사용한다고 말한다. slow pathway 와 fast pathway를 거친 후 lateral connection으로 fusion 하는 것이 큰 그림이라고 보면 될 듯 하다.
Slow pathway
- Spatiotemporal volume 을 가지고 있는 any convolution model이 될 수 있음
- 핵심 개념 : input frame의 킨 temporal stride τ (τ frame 마다 하나씩 처리)
- 일반적으로 τ=16 을 사용 (1초당 2 frame sampling )
- Sampling frame 수가 T 라면 raw clip length = T x τ
Fast pathway
- High frame rate
- Small temporal stride $\frac{τ}{α}$ (α>1)을 사용 (α : Fast와 Slow pathway 의 frame rate ratio)
- α = 8 을 일반적으로 사용
- α 의 존재가 SlowFast의 핵심
- Sampling frame = α x T
- High temporal resolution feature
- Path 전체의 high resolution 을 유지하기 위해 classification 전의 global pooling 전까지 Temporal downsampling layers (temporal pooling , time-strided convolutions) 사용 X
- 즉, 네트워크 전체에 high resolution feature를 유지
- Low channel capacity
- 좋은 정확도를 달성하기 위해 lower channel capacity 사용한 점에서 다른 model과 구별
간단히 말해서, 우리의 Fast 경로는 Slow 경로와 유사한 convolution 네트워크지만 Slow pathway의 β(β <1) channel ratio를 갖는다. 일반적인 값은 우리 실험에서 β = 1/8이다. common layer의 계산(FLOP)은 종종 channel scaling ratio 측면에서 2 차적이다. 이것이 Fast pathway가 Slow pathway보다 계산 효율성을 높이는 이유다. Instantiation에서 Fast pathway는 일반적으로 전체 계산의 약 20 %를 차지한다. 흥미롭게도 Sec.1 에 따르면 영장류 시각 시스템에서 망막 세포의 ~ 15-20%가 M- 세포(빠른 움직임에 민감하지만 색상이나 공간 세부 사항이 아님)다.
낮은 channel capacity는 spatial semantic을 나타내는 능력이 약한 것으로 해석될 수도 있다. 기술적으로 우리의 Fast pathway는 spatical dimension에 대한 특별한 처리가 없으므로 Fast pathway의 spatical modeling capacity는 채널 수가 적기 때문에 느린 경로보다 낮아야 한다. 우리 모델의 좋은 결과는 Fast 경로가 spatial modeling 능력을 약화시키면서 temporal modeling 능력을 강화하는 것이 바람직한 trade-off임을 시사한다.
실험에서도, Fast pathway 에서 spatial capacity를 약화시키는 다양한 방법을 실험(input spatial resolution 감소, RGB information 제거 등)
- 모두 우수한 정확도를 제공할 수 있으며 공간 용량이 적은 lightweight Fast pathway 가 유용함을 시사
Lateral connections
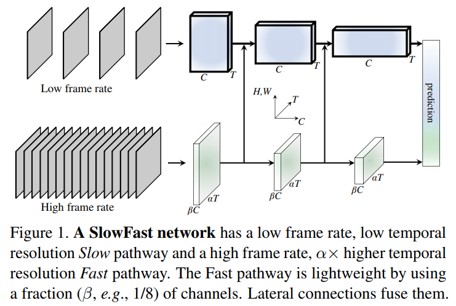
- 두 pathway의 정보는 fusion되어 있으므로 서로 다른 pathway가 학습한 representation 인식 불가
- optical 기반 2-stream network를 융합하는 데 사용된 leteral connection을 사용해 구현
- Fast pathway 의 feature 를 Slow pathway 로 fusion 하는 단방향 연결 사용
- 각 pathway 출력에 대해 global average pooling, concat, fully-connected layer
Instantiations
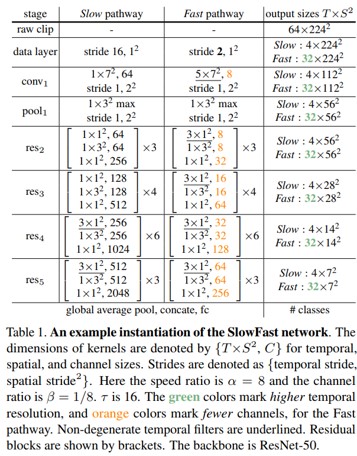
- SlowFast idea 를 다른 backbone 및 implementation specific 으로 instantiation 할 수 있음
- Spatiotemporal size : T x S^2 (T : temporal length, S : height and width of a square spatial crop)
- Slow pathway
- T=4, τ = 16 인 64 frame 의 raw clip
- Temporal downsampling X ( 성능 저하 방지 )
- Fast pathway
- α = 8 및 β = 1/8
- temporal resolution (초록색) 높고 channel capacity(주황) 낮음
- 모든 block에서 non-degenerate temporal model
- Lateral connections
- Fast 에서 Slow pathway 로 fusion
- Slow pathway feature shape = {T, $S^{2}$ , C}
- Fast pathway feature shape = {αT, $S^{2}$ , βC}
- Time-to-channel
- {αT, $S^{2}$ , βC} -> {T, $S^{2}$ , αβC} 으로 reshape과 transpose
- 의미 : 모든 α frame 을 one frame 의 채널로 pack
- Time-strdied sampling
- 단순히 모든 α frame 중 하나를 sampling
- {αT, $S^{2}$ , βC} -> {T, $S^{2}$ , βC}
- Time-strided convolution
- 2βC output channel과 stride = α를 사용하여 5x$1^{2}$ 커널의 3D convolution 을 수행
- Lanteral connection 의 output 은 Slow pathway 와 summation or concatenation 으로 fusion
Experiments: Action classification
Evaluate dataset
Kinetics-400
- 400 classes , 240k training , 20k validation videos
Kinetics-600
- 600 classes , 392k training , 30k validation videos
Kinetics dataset은 Top-1 & Top-5 classification accuracy로 평가
Charades
- 157 classes , 9.8k training , 1.8 validation videos , multi-label classifiaction
Charades dataset은 mAP로 평가
Training.
Kinectics dataset에 대해서 ImageNet과 같은 어떠한 pre-training을 하지 않고 random initialization (“from scratch”) 로 학습하였다. synchronized SGD를 사용하였고 자세한 내용은 Appendix를 참고하면 된다. full video에서 (αT × τ) frame random sample을 함. 따라서 Slow pathway 는 T frame, Fast pathway는 αT frame을 가진다. 224x224 random crop 사용
Inference.
- 일반적인 관행에 따라 비디오에서 시간 축을 따라 10 개의 클립을 균일하게 샘플링
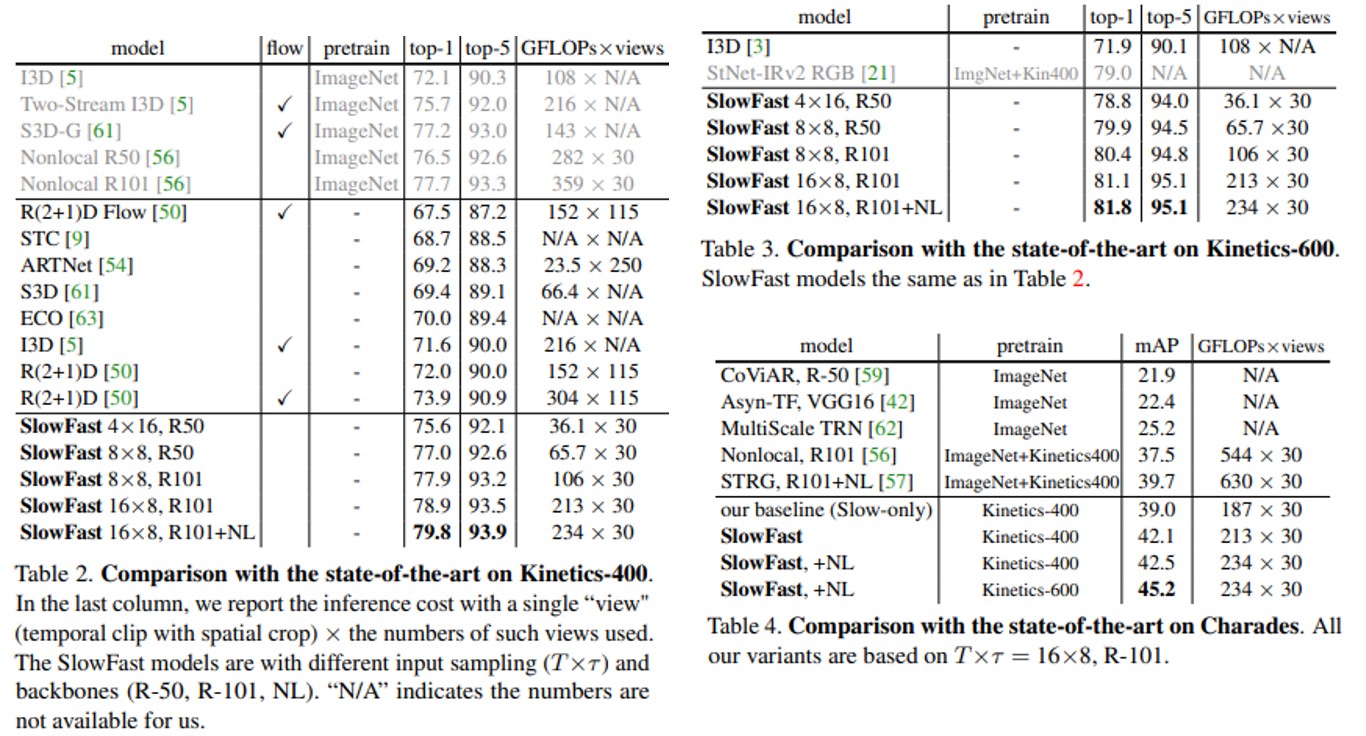
Main Results
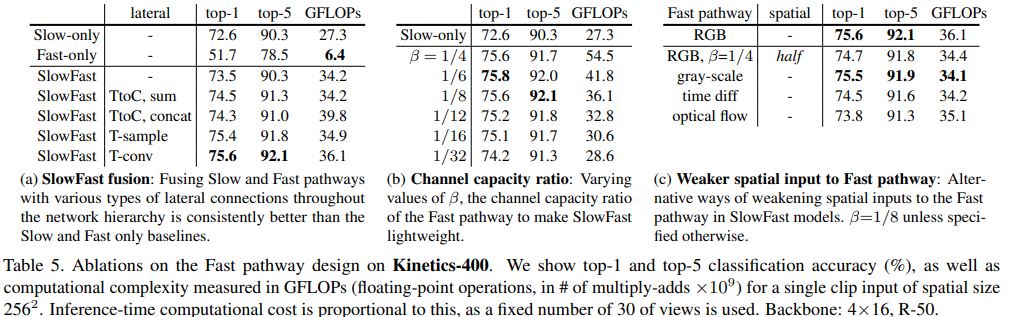
Ablation Experiments
Experiments: AVA Action Detection
Dataset : AVA dataset
- 인간 행동의 시공간적 위치에 초점을 맞춤
- 437개의 movie에서 가져옴
- 초당 1 frame에 시공간 labeling되어 있으며 모든 사람은 bounding box로 주석
- 배우의 위치 파악은 쉬운 편이며 행동 감지가 어려운 편
- AVA v2.1 dataset을 사용
- 211k training, 57k validation video segment
- 60 classes
- frame-level IOU threshold of 0.5을 평가
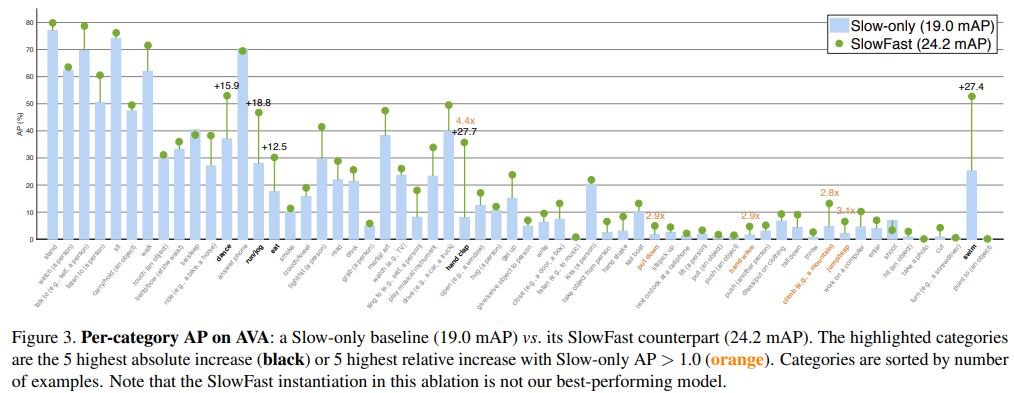
Main Results
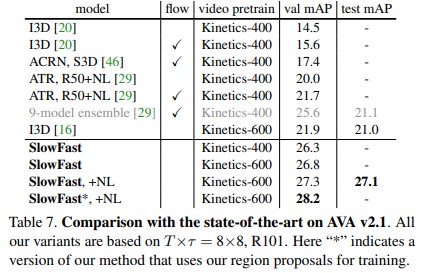
Conclusion
- Time axis 는 special dimension 이기 때문에 time axis 를 따라 속도를 비교하는 architecture 설계
- SlowFast 개념이 video recognition 에 대해 추가적인 연구를 하기를 희망
Leave a comment