Video Transformer Network 리뷰
Updated:
Video Transformer Network 리뷰
논문 다운 링크
https://arxiv.org/pdf/2102.00719.pdf
Abstract
Video Transformer Network 제안
- 전체 Video sequence information에 attention하여 classification하는 방식
- 2D spatial network에서 구축
- 기존의 sota model보다
- 16.1배 빠른 학습 시간
- 5.1배 빠른 inference 시간
- single end-to-end pass를 통해 1.5배 적은 GFLOPs
- Dataset : Kinetics-400
Introduction
- ConvNet은 많은 분야에서 sota의 결과를 가져왔지만, 최근에는 Transformer-based model이 많은 분야에서 좋은 성능을 가져옴.
- 기존의 temporal dimension 를 input clip에 straight로 추가한 것과는 달리 우리는 3D netowrk에서 벗어나는 것에 초점을 맞춤
- sota 2D 아키텍처에서 spatial feature 학습하고 attention mechanism을 사용해 data flow 에 temporal information를 추가
- 기존의 video recognition 에서는 10초도 길어서 2초로 나눠서 학습하는데 몇 시간에서 몇 분짜리 영상을 수 초의 snippet 으로 파악할 수 있다는 것은 직관적이지 않음
- VTN의 temporal processing component는 Longformer 기반임
- 제안하는 framework’s structure component
- 2D Spatial backbone은 아무거나 상관 없음
- Attention-based module
- more layer, more head 해도 상관 없음
- long sequence가 가능한 transformer model이면 상관 없음
- Classification head를 변경하여 다른 video-based task 사용 가능
Related Network
Spatial-Temporal Network
- 3D ConvNet, Two-stream architecture, I3D
- Non-local Neural Network
- Self-attention에 좋은 결과를 얻을 수는 있지만 짧은 클립에 한정적이기 때문에 FBO(Feature Bank Operator)가 제안되었었다
- FBO는 long-term feature가 필요하고, feature extraction backbone의 end-to-end training을 지원할 만큼 효율적이지 않음
- SlowFast
- X3D
Transformer in computer vision
- NLP에서 좋은 성능을 보임
- Deep ConvNet에서도 좋은 성능을 보임
- Image classification : ViT, DeiT
- Object detection and panoptic segmentation : DETR
- Video instance segmentation : VisTR
Applying Transformer on long sequences
- BERT & RoBERTa
- Based language representation model, large unlabeled text에서 학습하고 target task에 대해 fine-tuning
- BERT 모델이나 일반적인 transformer model 의 단점
- 긴 sequence 를 처리하는 능력 : $𝑂(n^{2})$ 의 복잡도를 가지는 self-attention 연산
- Longformer
- $𝑂(n)$ 의 복잡도를 가지는 attention mechanism -> lengthy document 처리 가능
- Sliding window로 처리되는 local-context self-attention + task-specific global attention
- Stacking up multiple sindowed attention layer : larger receptive field 를 가짐
- 따라서 전체 sequence 에서 정보를 integrate 가능
- Global attention part 는 pre-selected token(예: [CLS] 토큰)에 초점을 맞추고 input sequence에서 다른 모든 token에 주의를 기울일 수 있음
Video Transformer network
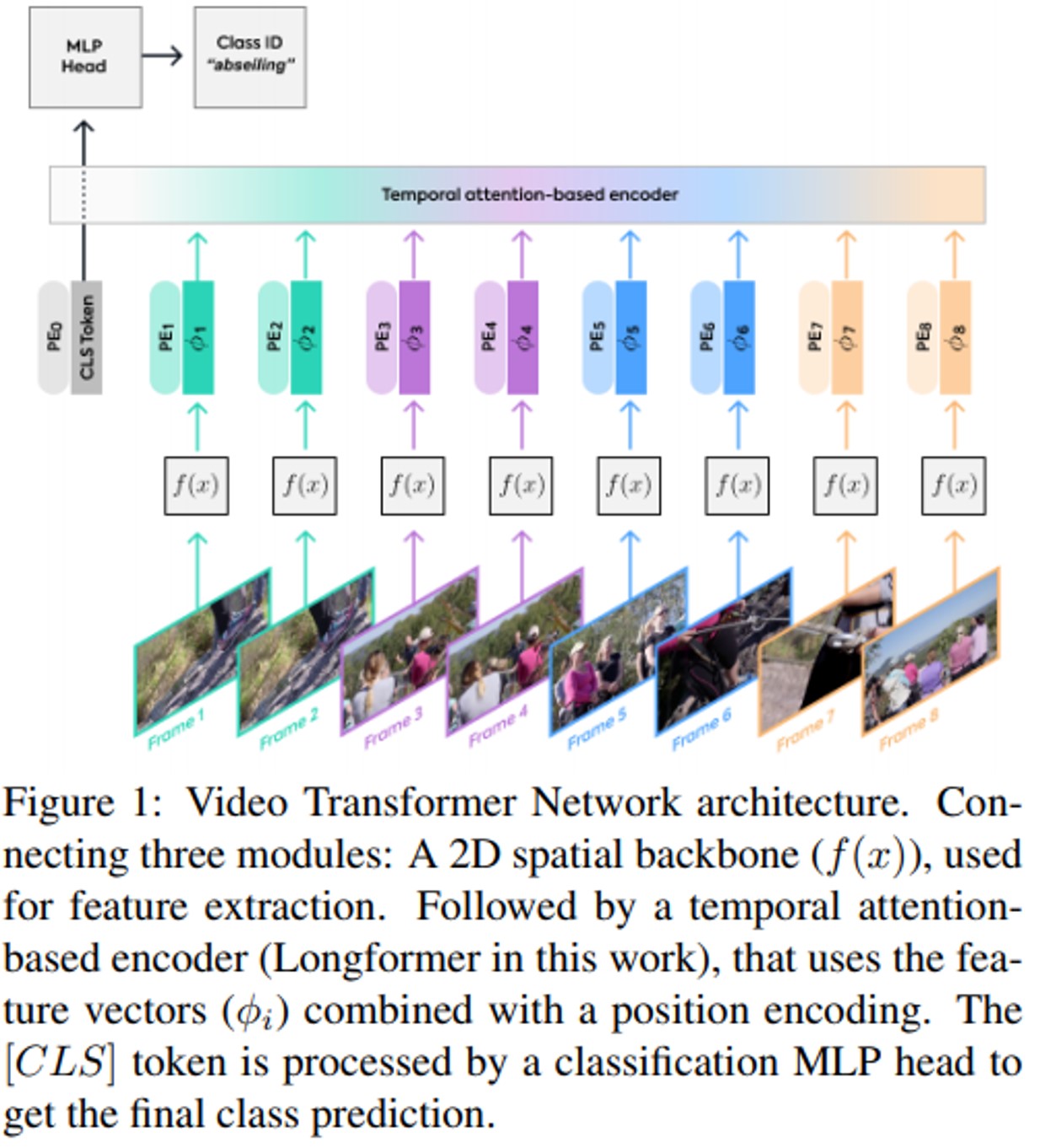
Video Transformer Network (VTN)
- frame level 에서 objective task head 까지 single stream 으로 동작
- 3가지 consecutive part로 구성
- 2D spatial feature extraction
- Temporal attention-based encoder
- Classification MLP head
- Memory 문제로 인한 3가지 inference 방법 제안
- end-to-end 방식으로 전체 video 처리
- video 를 chunk 처리 후 feature 추출 후temporal attention-based encoder 에 적용
- 모든 frame feature 를 추출 후 다음 temporal encoder에 입력
Spatial backbone (2D spatial feature extraction)
- Feature extraction module
- deep/shallow , pre-trained/not , conv/transformer-based , weight 고정/학습 과 상관 없는 2D image any network 사용 가능
Temporal attention-based encoder
- Transformer : 동시에 처리할 수 있는 token 의 수가 제한됨
- Video 와 같은 긴 입력을 처리하고, distant information 의 연결을 incorporate 하는 능력 제한할 수 있음
- Inference 동안 전체 video 를 처리하는 방법 제안 -> longformer 사용
- Linear computation complexity 를 가능하게 하는 sliding window attention 사용
- Encoder 의 input 은 spatial backbone 에서 나온 feature vector
- Feature vector 는 1D token 역할을 함
- BERT 처럼 CLS(special classification) token 을 feature sequence 앞에 추가
- 1) Longformer layer 를 통해 sequence 를 통과한 후
- 2) 이 CLS token 과 관련된 feature 의 final state 를 비디오의 최종 representation 으로 사용하고 지정된 classification task head에 적용
- Longformer는 또한 그 특별한 [CLS] 토큰에 대한 global attention을 유지
Classification MLP head
- Final predicted category 를 위해 MLP head 사용
- MLP head 는 GELU activation function 과 dropout 을 포함
- Input token representation 은 먼저 layer normalization
Looking beyond a short clip context
- 일반적인 접근 방식인 3D Conv 기반 네트워크는 작은 spatial scale 과 적은 수 의 frame 에서 동작
Video Action Recognition with VTN
2D feature extractor backbone 실험
Implementation Details
- Longformer 와 MLP classification head : 평균 0, 분산 0.02 인 정규 분포에서 random 초기화
- SGD optimizer
- Batch size : 16(ViT-B-VTN), 32(R50/101-VTN)
- Learning rate : $10^{-3}$
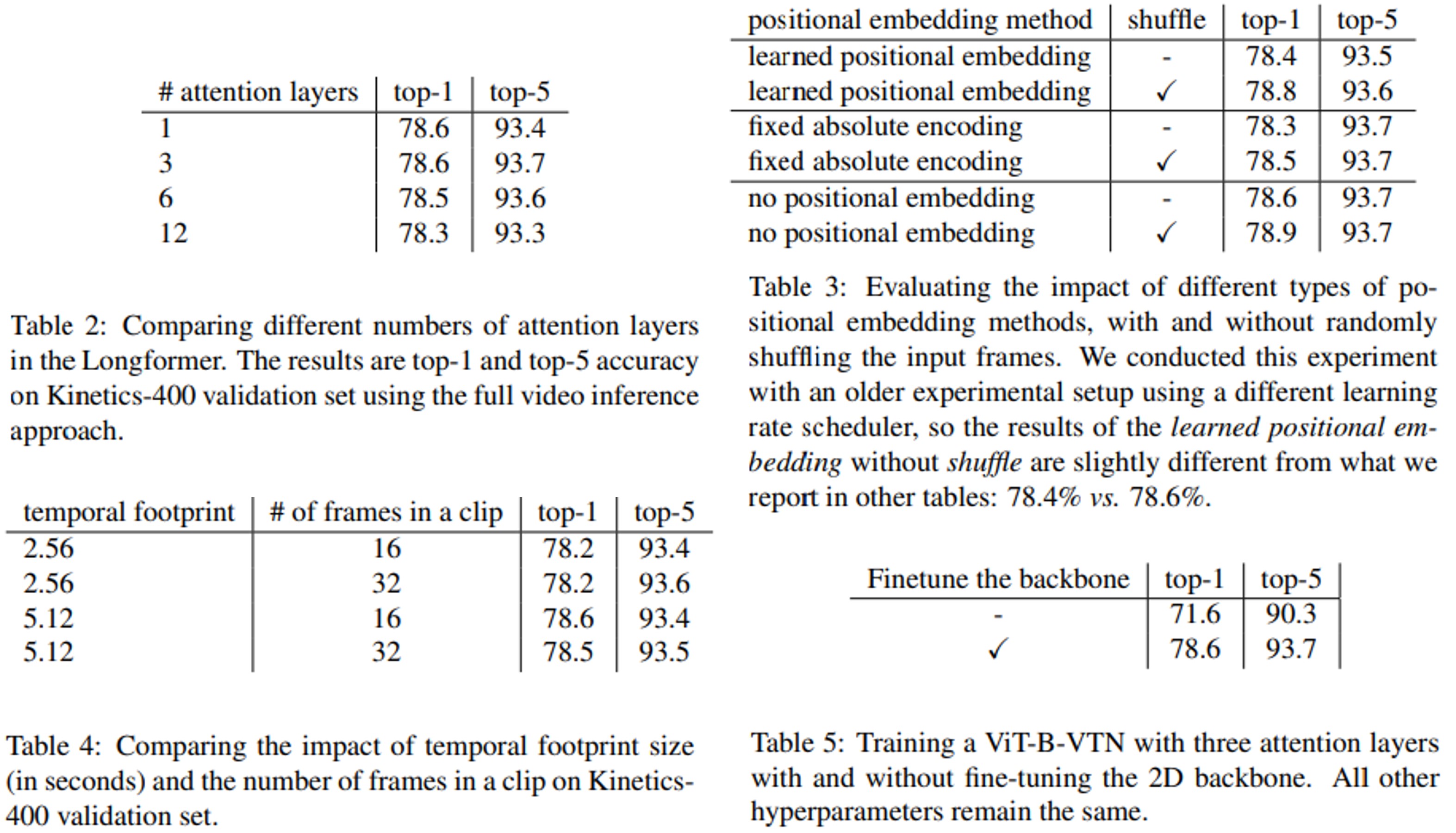
Experiments
- Kinetics-400 dataset에 대해 실험
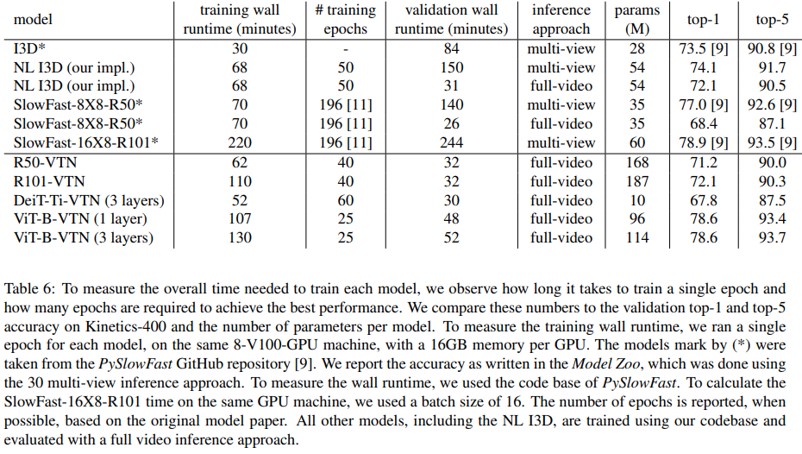

Conclusion
- Transformer-based framework 제안
- 테스트 시, long video를 처리 가능
- 현재의 데이터셋은 long-term video 처리 능력을 테스트하는데 이상적이지 않음
- 미래에 적합한 데이터셋이 구축된다면 VTN같은 모델이 더 좋은 성능을 보일 것임
Leave a comment