Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset 리뷰
Updated:
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset 리뷰
논문 내용 정리하였습니다.
논문 다운 링크
https://arxiv.org/abs/1705.07750
Abstract
- Action Recognition을 위한 새로운 Dataset인 Kinetics dataset 만듦
- 400 classes –> 2021년 기준 700 classes
- class 당 400개가 넘는 clip
- YouTube에서 realistic한 장면
- Two-stream Inflated 3D ConvNet (I3D) 제안
- 2D convNet inflation 기반
- Kinetics로 pre-training 후 성능 증가
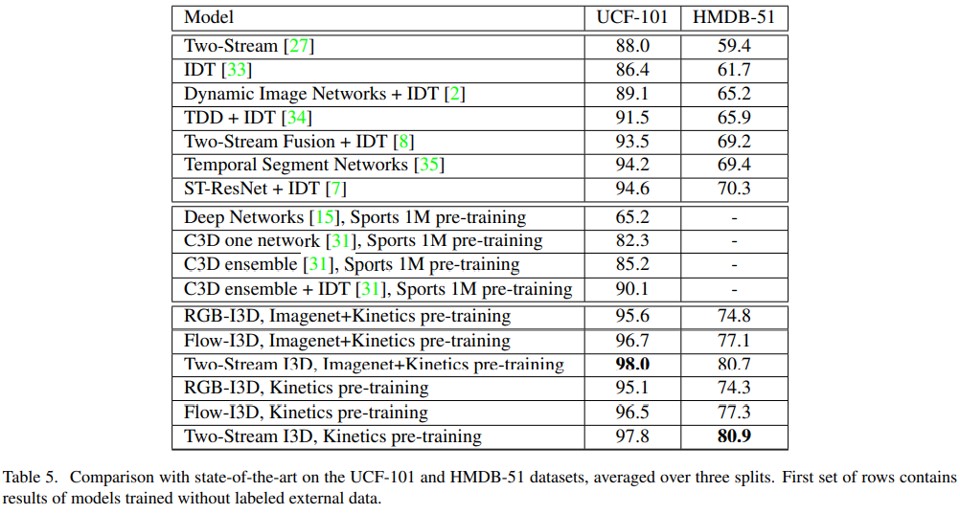
- HMDB51 : 80.9%
- UCF-101 : 98.0%
Introduction
- 기존 Action Recognition dataset의 한계
- 10k 정도 밖에 되지 않는 video 수
-
2배 이상 큰 Kinetics Human Action Video Dataset 사용
- 다양한 대표적인 Network에서 Kinetics dataset으로 pre-training 후 성능 비교
- HMDB51, UCF-101
- Two-Stream Inflated 3D ConvNet 모델 제안
- filter와 pooling layer를 3D로 확장
Action classification Architectures
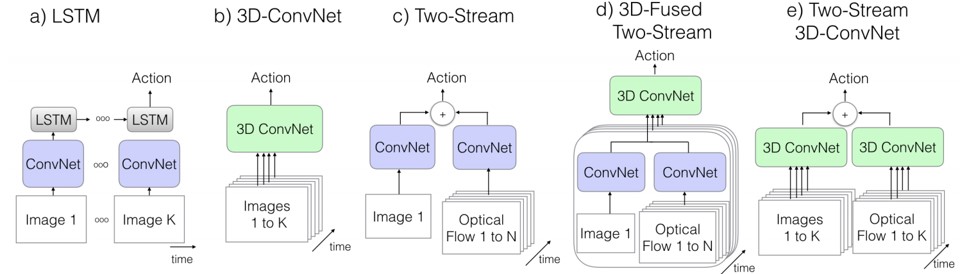
-
The Old I: ConvNet+LSTM
- 각 프레임마다 CNN을 이용해 독립적으로 feature 추출
- Temporal structure를 무시하는 구조이며 학습이 expensive
-
The Old II: 3D ConvNets
- SpatioTemporal information을 잘 얻을 수 있음
- 파마리터의 증가로 학습이 힘듦
- 최소한의 성능 보장
-
The Old III: Two-Stream Networks
- 10개의 Optical flow와 RGB frame 사용
- RGB frame을 사용하는 경우보다 모든 경우에서 높은 성능
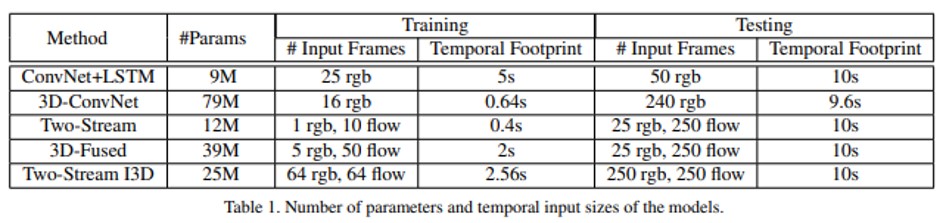
- The New: Two-Stream Inflated 3D ConvNets
- 3D ConvNet이 ImageNet 2D ConvNet 설계 및 선택적으로 학습 된 매개 변수로부터 혜택을 받을 수있는 방법을 보여줌
- Inflating 2D ConvNets into 3D
- ImageNet data를 이용해 image 2D classification 문제에 대해 학습시킨
- 2D ConvNet을 3D ConvNet으로 변환
- 2D architecture에서 모든 filter와 pooling kernel을 확장
- N x N 필터 -> N x N x N 필터
- The New: Two-Stream Inflated 3D ConvNets
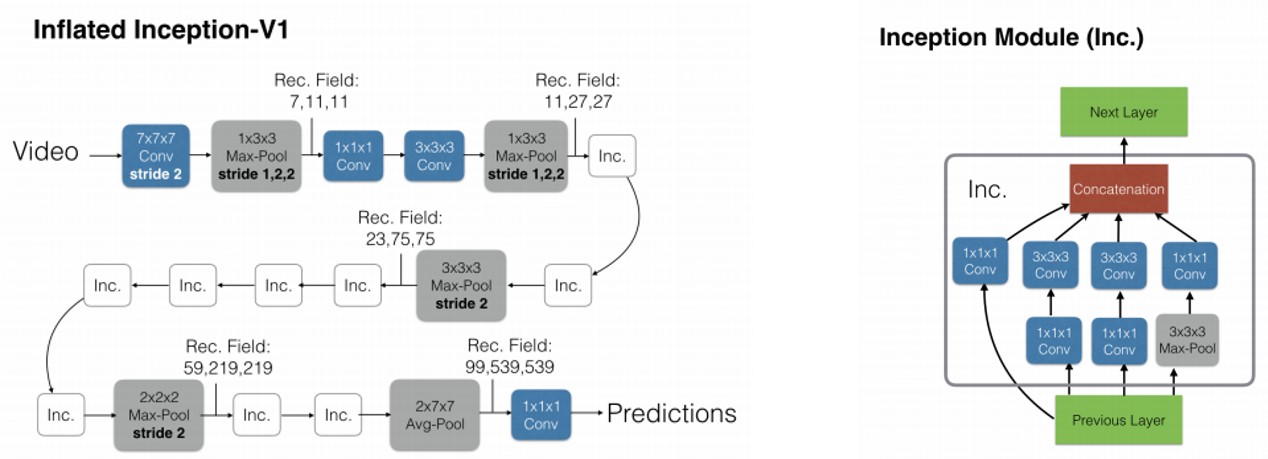
- Implementation Details
- Inception-V1 network로 ImageNet pre-training
- Batch normalization, ReLU activation function
- SGD (momentum set 0.9)
The Kinetics Human Action Video Dataset
- Person Actions (singular)
- 그리기, 음주, 웃음, 펀치
- 개인-개인 행동
- 포옹, 키스, 악수
- Person-Object Actions
- 개봉 선물, 잔디 깎기, 설거지
-> 400 개 이상의 clip이 포함된 400개의 human action class
Experimental Results And Evaluations
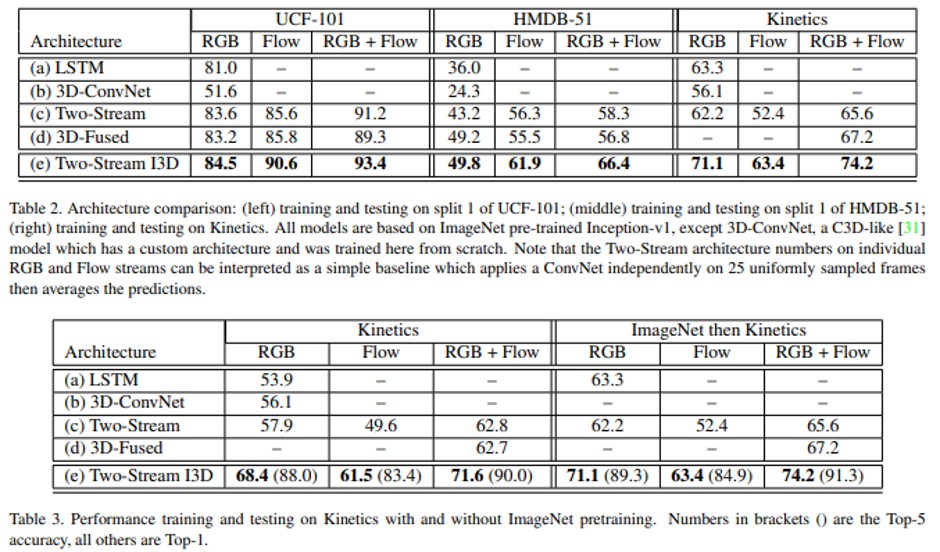
Discussion
-
ImageNet에서 ConvNet을 사전 훈련 할 때 이점이 있었던 것처럼 Kinetics Dataset에 대한 사전 훈련에 상당한 이점이 있다는 것은 분명
-
Kinetics dataset으로 pre-traning의 효과는 더 지켜봐야 함
Leave a comment